
매뉴얼
- Home
- Manual
Fraudit 개요
Fraudit은 어떤 소프트웨어인가요?
- Fraudit은 부정적발, 분식회계탐지 등을 위한 고급 감사 소프트웨어로 Python 베이스 소프트웨어입니다.
부정적발, 분식회계탐지를 주목적으로 개발하였지만 일반 데이터 분석 툴로도 확장성이 뛰어난 소프트웨어입니다. - 많은 데이터 분석가들은 여러 가지 어플리케이션을 사용합니다. MS Excel, VisualBasic, MicrosoftAccess, SAS 등은 각각의 응용 분야의 강점을 가지고 있습니다.
그러나 그 어떤 것도 기업 데이터의 분석이나 심도 있는 데이터 마이닝을 위해 특별히 만들어지지 않았습니다. 어떤 것은 일반적인 데이터베이스고 어떤 것은 통계적인 응용 프로그램입니다.
이러한 어플리케이션을 사용하다보면 다음과 같은 필요성을 느끼게 되었습니다. - Windows, MacOS, 유닉스 서버에서 실행 가능한 cross platform
- 부정적발 및 분식회계 탐지에 특화된 템플렛
- 강력하지만 사용이 쉬운 언어 사용
- 방대한 양의 데이터를 분석할 수 있는 능력
- 전문 분석가에 모든 작업을 부탁하지 않고도 일반 분석가가 업무를 수행할 수 있게 하는 방법
- GUI 와 Console 모두를 사용할 수 있게 하는 Interface
- 이러한 요구에 맞는 제품을 찾기가 매우 매우 힘들기 때문에 Fraudit을 개발하게 된 것입니다.
Fraudit은 개념적으로 3가지 수준으로 구분됩니다. - level 1 : 기본적인 분석 단계를 지원하는 기초적인 절차(부정 적발에 국한되는 것이 아님)
- level 2 : level 1 절차를 지능적으로 결합하여 일반 분석가도 강력한 분석을 할 수 있도록 해주는 부정 적발 절차
- level 3 : level 2에 전문가 시스템을 사용하여 부정을 자동적으로 발견하는 절차
- Fraudit은 현재 부정적발 및 분식회계에 초점을 맞추고 있지만 실제로 다양한 유형의 데이터 분석(network logs, scientific data, 데이터베이스 지향 데이터 및 데이터 마이닝 등)에 사용될 수 있는 framework입니다.
왜 Fraudit을 사용할 필요가 있을까요?
- Fraudit은 다음과 같은 특징이 있습니다.
- Fraudit의 스크립팅은 강력하고 학습하기 쉬운 컴퓨터 언어인 Python을 기반으로 하고 있습니다.
경쟁 프로그램의 경우 자체 언어를 사용하는데 반하여 Fraudit은 전세계적으로 가장 인기있는 언어인 Python을 토대로 수천개의 라이브러리를 분석 목적에 맞게 인터넷을 통해서 무료로 다운로드 받을 수 있습니다. - Fraudit의 scriptlet 프레임워크는 스크립팅에 대한 관심이 있고 이를 만들 수 있는 능력이 있는 사람들에게 마법사 기능을 제공할 수 있습니다.
- Fraudit은 사용자가 스크립트 작성 방법(python)을 배울 수 있도록 도와줍니다.
예를 들어, 사용자가 for 함수와 같은 loop에 대하여 이해하고 있으면 그렇지 않은 사람보다 훨씬 더 효율적이고 효과적으로 분석을 할 수 있습니다.
Fraudit은 GUI에서 이용자가 하는 모든 일을 스크립트 코드를 보여줍니다. - Fraudit은 경쟁 프로그램에는 없는 고급 분석 루틴을 포함하고 있습니다. 예를 들어, 작업 및 시간 카드 데이터의 분석을 위하여 날짜별로 그룹핑을 할 수 있습니다.
- Fraudit은 윈도우, MacOS X, 리눅스 및 다른 많은 시스템에서 실행될 수 있습니다.
Fraudit과 ACL 또는 IDEA와의 관계는?
- 한마디로 Fraudit은 양 소프트웨어와 경쟁관계에 있습니다. 그러나 Fraudit은 파이썬 베이스라는 것이 가장 큰 장점입니다.
파이썬의 정규식(regular expression)을 그대로 사용할 수 있고 전 세계 개발자들, 데이터 분석가들의 주옥같은 코드를 그대로 활용할 수 있습니다.
Fraudit과 MS Excel과의 관계는?
- MS Excel은 수치 분석에 있어서 강력하고 오래된 어플리케이션입니다.
그러나 스프레드시트 프로그램은 전형적인 데이터베이스 중심의 분석이라기 보다는 임시(ad-hoc)분석에 더 적합합니다.
즉, 투자 또는 주택 담보 대출 일정과 같은 계산에는 Excel이 더 적합하지만 쿼리와 같은 분석에는 Excel은 덜 적합한 면이 있습니다.
Fraudit은 계층화(stratifying), 요약(summarizing), 매칭(matching), 조이닝(joining) 등을 전문적으로 처리할 수 있습니다. - Fraudit은 대규모의 데이터베이스에서 검색된 데이터를 사용하여 작업할 수 있습니다.
Excel은 약 100만개의 record를 처리할 수 있지만 메모리를 많이 사용하는 어플리케이션이므로 실제로는 40-50만개 이상의 record를 처리하기에는 무리가 있습니다.
Fraudit은 수천만개의 record를 처리할 수 있으므로(단지 컴퓨터 메모리에 제한을 받을 뿐) Excel에서 불가능한 규모에 대해서도 분석 기능을 제공합니다.
Fraudit과 Numpy/Scipy와의 관계는?
- Fraudit이 기업 데이터에 초점이 맞추어진 반면에 Numpy는 선형대수와 같은 과학적 목적에 초점을 맞추고 있습니다.
Numpy는 array(배열) 스토리지 및 표시에 특화되어 있으며 array 조작, 수학 등에 초점을 맞추고 있다. Numpy는 큰 행렬의 데이터로 빈셀을 포함하지 않는 것이 일반적입니다. - Fraudit은 데이터베이스를 연결하고 테이블에 데이터를 표시하는데 특화되어 있습니다.
array와 테이블 모두 유사하지만 양자는 추구하는 바(데이터 구조와 함수 등)가 상당히 다릅니다. Fraudit은 텍스트, 주소, 급여 등과 같은 데이터베이스 형식의 데이터를 주로 다룹니다.
Fraudit과 Pandas와의 관계는?
- Pandas 자체도 매우 훌륭한 2차원 표형태의 분석 툴입니다.
그러나 Pandas의 약점은 dataframe을 하나의 객체로 다루므로 그 안에서 column과 record를 분리하여 여러 가지 기능을 추가하기 위해서는 pandas 자체의 사용법에 매우 익숙해져야 합니다.
(경우에 따라서는 Numpy와 결합하여 해결해야만 합니다). - Fraudit은 Pandas와 유사하게 테이블(가로 세로로 구성된)을 주로 다루고 있으나, column과 record를 python의 기본 list로 구분하여 사용자가 직접 조건문을 적용하기가 매우 용이합니다.
Fraudit과 Pandas와의 관계는?
- Fraudit은 파이썬 베이스입니다. 엄밀히 말하면, Fraudit은 Python위에 구축된 모듈, 기능 및 루틴 세트입니다.
Python 만으로도 매우 강력한 데이터 및 텍스트 분석 플랫폼인데 Fraudit은 Python에 테이블 형식을 추가하고 많은 데이터 분석 함수를 제공합니다. - Fraudit은 파이썬으로 할 수 있는 모든 것을 다 할 수 있습니다. 또한 수천개의 라이브러리를 분석 목적에 맞게 인터넷을 통해서 다운로드 받을 수 있습니다.
왜 Python을 활용하는가?(VB, Java, Perl 등 보다)
- 왜냐하면 당연히 파이썬이 훨씬 좋고 배우기 쉽기 때문입니다! (인터넷에 찾아보길 바랍니다.)
Fraudit의 초기화면
Fraudit의 Workspace
- 【그림 2.1】에 표시된 Fraudit의 Workspace는 크게 세가지 주요 영역으로 구분되어 있습니다.
Menu bar, Object Tree/Disk explorer, Table tabs, 그리고 shell 입니다. 아래에서는 이에 대해서 자세히 설명하기로 합니다.
【그림 1】 Fraudit Main Screen
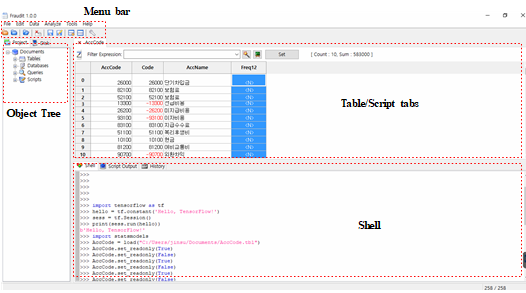
Object Tree
- Object Tree는 모든 데이터베이스 연결과 테이블을 보여줍니다. 목록에서 테이블을 더블 클릭하면 오른쪽 Table tab에서 보여지게 됩니다.
- Object Tree의 테이블은 자동으로 저장되지 않으며 프로그램이 닫힐 때 삭제됩니다.
왜냐하면 많은 루틴이 수백 또는 수천개의 하위 테이블을 생성하기 때문입니다. 이들을 디스크에 저장하는 것은 실용적이거나 바람직하지 않습니다. 그러므로 다시 사용하고자 하는 테이블은 반드시 저장하여야 합니다.
Table/Script Tabs
- Fraudit 화면의 가장 중요한 부분은 Table의 tab 브라우저와 Script tab입니다.
스프레드시트와 같이 보이는 테이블에 column, record, 셀의 값을 추가, 삭제, 변경할 수 있으며 filter, sorting 및 메뉴에서 제공하는 기본 기능 등을 적용할 수 있습니다. - Scripts는 Editor file(파이썬으로 확장자 .py)에서 보여집니다. 일반적으로 파이썬 문법에 따라 Script 를 넣을 수 있으며 자르기, 복사, 붙여 넣기 등의 명령을 할 수 있습니다. 이는 Scripts 장에서 보다 자세히 설명하기로 합니다.
Shell, Script Output, and History
- Shell을 사용하여 명령을 한번에 하나씩 입력하여 결과를 생성할 수 있습니다.
또한 Fraudit에서 전체 스크립트를 실행하면 스크립트에 생성된 모든 변수를 Shell에서 사용할 수 있게 됩니다(Python console 이나 Python editor와 거의 동일한 기능을 수행한다고 이해하기 바랍니다).
그러면 전체 절차를 다시 실행하지 않고도 추가 명령을 수행하거나 결과 데이터를 검사할 수 있습니다. - Fraudit 메뉴와 대화 상자에서 수행하는 모든 작업은 Shell의 호출로 변환됩니다. 프로그램 대화 상자를 실행하면서 Shell에 어떤 Script가 생성되는지를 유심히 확인하기 바랍니다.
시간이 지나면서 각 명령어가 무엇을 하는지에 대해 배우게 되고 Shell에 대해 더 익숙하게 될 것입니다.
익숙하게 되면 메뉴을 사용하는 것보다 shell에서 직접 script를 하는 것이 더 빠르고 효율적일 수 있다는 것을 금방 알게 될 것입니다. - GUI와 Shell은 양방향이며, 이는 사용자가 GUI에서 변경하는 모든 항목(예: 테이블에서의 셀 값 수정 등)도 Shell 변수에서 변경됨을 의미합니다. 마찬가지로, Shell 변수에서 변경하는 모든 항목이 GUI에 즉시 반영됩니다.
- Shell에서 임시 분석(ad-hoc analysis) 또는 테스트 명령을 수행하는 것이 매우 편리하다. 이는 Scripts 장에서 보다 자세히 설명하기로 합니다.
Fraudit에서 명령을 실행하는 방법
- Fraudit에서 명령을 실행하는 방법에는 다음과 같이 3가지가 있습니다.
- Menu and Toolbar : Menu and Toolbar는 각 기능을 안내하는 대화 상자로 이동하도록 합니다.
- Shell : 【그림 1】의 하단에 표시된 Shell을 사용하여 스크립트 명령어를 한 번에 한 줄씩 입력할 수 있습니다. 이 때 Python의 문법을 그대로 사용할 수 있습니다. 이는 임시 분석 또는 테스트 명령 호출을 수행하기 위한 좋은 방법입니다.
- Scripts : Script는 가장 강력한 인터페이스입니다. Script를 사용하면 프로그래밍 구조를 루프와 같은 방식으로 사용할 수 있으며, 여러 분석을 완전히 자동화 할 수 있습니다.
Menu and Toolbar
- Menu and Toolbar를 사용하면 다양한 Fraudit 기능을 수행할 수 있습니다. 메뉴에서 옵션을 선택할 때마다 Fraudit는 Shell에 관련 Script를 표시합니다(메뉴와 대화 상자는 Script를 생성하여 Shell에서 실행하는 체계를 가집니다).
- File Menu : File Menu는 ① 테이블 및 ② 데이터베이스에 대한 조작 기능을 제공합니다.
행과 열을 테이블에 추가하고, 열 유형과 같은 테이블 속성을 수정하고, 데이터베이스 연결을 생성하고, 데이터베이스 쿼리를 실행할 수 있습니다(그 결과 표가 생성됨). 또한 Fraudit에 대한 기본 설정 옵션을 이 메뉴에서 설정할 수 있습니다. - File Menu : Edit Menu에는 복사, 잘라내기, 붙여 넣기, 찾기, 바꾸기 등 대부분의 편집 메뉴의 표준 기능과 기능이 있습니다.
- Data Menu : Data Menu는 테이블 내의 데이터를 조작하는 기능을 제공합니다.
하위 메뉴로는 Select, Join, Stratify, Summarize, pivot table 등이 있습니다. - Analyze Menu : Analyze Menu는 특정 분석을 실행하는 기능을 제공합니다.
- Add Percentage Column : 특정 칼럼의 전체 합산에서 각 레코드의 차지하는 비율을 백분율로 보여줍니다.
- Add Cumsum Column : 특정 칼럼의 레코드 순서대로 누적합산액을 계산하여 줍니다.
- Add Cumsubtract Column : 특정 칼럼의 레코드 순서대로 누적차감액을 계산하여 줍니다.
- Add Shift Column : 특정 칼럼의 레코드의 순서를 하나씩 내리거나 올린 칼럼을 보여줍니다.
- Add Vlookup Column : Excel의 Vlookup기능과 유사한 기능을 제공합니다.
- Duplicates : 중복된 값이 있는 경우를 찾아줍니다.
- Gap : 순서로 나열된 것 중에 누락되어 있는 경우를 찾아줍니다. 이러한 기능은 중복된 송장 또는 지급, 누락된 문서 또는 정령 문제를 발견하는데 유용합니다.
- Matching By Value : 테이블에서 조건과 일치하는(Matching) 값을 가지는 칼럼을 찾아줍니다.
- NonMatching By Value : 테이블에서 조건과 일치하지 않는(Matching) 값을 가지는 칼럼을 찾아줍니다.
- Matching By Expression : 테이블에서 조건을 산식으로 정하고 이 산식과 일치하는(Matching) 칼럼을 찾아줍니다.
- NonMatching By Expression : 테이블에서 조건을 산식으로 정하고 이 산식과 일치하지 않는(NonMatching) 칼럼을 찾아줍니다.
- Add ZScore Column : 이상치를 발견하는 방법은 많지만, Zscore 계산은 가장 간단하면서도 좋은 방법 중 하나입니다.
이 메뉴를 통해서 Zscore 칼럼을 추가하여 이상 징후를 선택하고 Outliers와 NonOutliers를 선택할 수 있습니다. - Select NonOutliers : 최소값과 최대값을 직접 입력하고 이 값 사이에 있는 NonOutliers를 뽑아주는 기능입니다.
- Select NonOutliers by ZScore: ZScore 값을 입력하고 이 값 사이에 있는 NonOutliers를 뽑아주는 기능입니다.
- Select Outliers : 최소값과 최대값을 직접 입력하고 이 값 범위의 밖에 있는 Outliers를 뽑아주는 기능입니다.
- Select Outliers by ZScore: ZScore 값을 입력하고 이 값 범위의 밖에 있는 Outliers를 뽑아주는 기능입니다.
- Add Cusum Column : 테이블의 각 record 값의 차이를 누적한 것을 별도의 칼럼으로 보여줍니다. Cusum은 어떤 곡선의 전반적인 방향을 직관적으로 알려줌으로써 추세의 패턴을 알 수 있게 도와줍니다.
- By Regression Slope : 회귀분석 결과 기울기를 보여주는 것입니다. 회귀분석에 대한 자세한 설명은 통계 교과서를 참고하기 바랍니다.
- By Handshaking Slope : 모든 레코드 간의 기울기를 계산한 칼럼을 추가해줍니다.
- By High_Low Slope : minimum X, Y 와 maximum X, Y 간의 기울기를 구하는 것입니다.
- Sampling Menu : 샘플링 분석을 실행하는 기능을 제공합니다.
- Tools Menu : 각종 추가 분석을 실행하는 기능을 제공한다. 향후 지속적으로 업데이트 될 메뉴입니다.
| 메뉴명 | 주요기능 |
|---|---|
| Set Project Folder | 프로젝트 폴더를 생성하고 프로젝트를 관리할 수 있도록 해줍니다. Fraudit을 처음 실행할 때 적어도 하나 이상의 프로젝트 폴더가 있어야 하므로 자동으로 생성하도록 요구합니다. |
| New Table | 새로운 테이블을 생성하여 줍니다. 이 버튼을 누르면 Table Properties 상자가 보이면서 칼럼명과 데이터 형태, 포맷을 정하고, 테이블명을 입력할 수 있게 됩니다. 테이블을 저장하려면 Save 또는 Save As 버튼을 누릅니다. |
| New Database Table | 데이터베이스에 연결할 수 있도록 마법사 기능을 제공합니다. ODBC, SQLite, MySQL, PostgreSQL, Oracle 데이터베이스와 연결할 수 있도록 해줍니다(향후 업그레이드시 데이터베이스의 종류가 추가될 예정). |
| New Query | 데이터베이스에 연결한 후 query 명령을 할 수 있도록 해줍니다. |
| New Script | Python 스크립트를 작성할 수 있는 에디터를 생성합니다. 이 에디터를 통하여 작성한 스크립트를 확장자 .py로 저장하여 실행시킬 수 있습니다. |
| Open | Fraudit Table을 엽니다. |
| Import | Excel, CSV 등의 파일을 불러와서 Fraudit Table로 변환해 줍니다. |
| Filter | Filter 기능을 제공합니다. Filter는 와일드카드와 Python의 정규식이 모두 사용가능합니다. |
| Sort | Sort는 정렬을 해주는 기능으로 여기서는 Full Sort를 해줍니다. 즉, 여러개의 칼럼에서 조건을 동시에 걸 수 있게 해줍니다. |
| Transpose | 테이블의 칼럼과 레코드의 방향을 바꾸어 줍니다. Excel의 행렬 바꾸기 기능과 유사한 기능입니다. |
| Row | 테이블의 Row를 삽입(insert)하거나 아래에 추가(append) 또는 삭제(delete)합니다. |
| Save | 테이블을 저장합니다. |
| Save As | 테이블을 다른 이름으로 저장합니다. 다른 이름으로 저장하게 되면 다음에 불러올 때 테이블명이 저장된 다른 이름으로 변경됩니다. |
| Export | 테이블을 Excel 또는 CSV 파일로 Export(내보내기) 합니다. |
| Copy Table | 선택한 테이블을 복사(copy) 한다. |
| Rename Table | 선택한 테이블명을 변경합니다. 다만, 이 테이블명은 탭상에서만 변경이 되고 파일 상으로는 변경전 테이블이 그대로 존재하게 됩니다(즉, ad-hoc분석을 위해서 테이블명을 일시적으로 변경하는 것입니다). 따라서, 이 기능은 특별한 경우가 아니면 자주 사용하는 것을 권장하지 않습니다. 테이블명을 변경하게 되면 변경후 테이블과 변경전의 테이블이 탭상에 동시에 존재하게 됩니다. 변경후 테이블에서 작업을 저장하게 되면 그 내용이 변경을 반영하기 위해서는 테이블명을 변경한 후의 테이블을 저장하면 변경전의 테이블에 저장됩니다. |
| Close Table | 선택한 테이블을 닫습니다. 하드디스크에서 삭제하는 것은 아닙니다. |
| Delete Table | 선택한 테이블을 하드디스크에서 삭제합니다. 따라서 이 기능은 신중하게 실행하여야 합니다. |
| Table Properties | 선택한 테이블의 칼럼명, 데이터 형식, 포맷, 산식 등을 정할 수 있으며 칼럼의 표시 순서를 변경할 수 있습니다. |
| Page Setup | 인쇄할 페이지를 세팅합니다. |
| Printing Review | 인쇄 미리보기 기능입니다. |
| Preference | 일반 기본 설정을 변경할 수 있습니다. 필요에 따라 커스텀마이징도 가능합니다. |
| 메뉴명 | 주요기능 |
|---|---|
| Find and Replace | 특정 value, string 등을 검색하여 주고 이를 일괄적으로 변경해주는 기능입니다. |
| Find Next | Find and Replace 메뉴를 실행한 후에 해당 value, string 등을 순서대로 찾아주는 기능입니다. |
| Go To Row | 특정 Row로 바로 이동하는 기능입니다. |
| Copy | 특정 셀, 칼럼, 레코드를 복사하는 기능입니다. |
| Paste | 복사한 값을 붙여넣기 하는 기능입니다. |
| Clear Script Output | Script Output의 내용을 지우는 기능입니다. |
| Clear History | History의 내용을 지우는 기능입니다. |
| 메뉴명 | 주요기능 |
|---|---|
| Select | 특정 조건에 해당하는 레코드를 선택하여 별도의 테이블로 구성해줍니다. 분석하기 전에 테이블을 필터링하고 테이블에서 찾는 것이 유용합니다. |
| Join | 2개의 테이블에 대하여 조건을 설정하여 함께 결합할 수 있습니다. Join 기능은 데이터베이스 query joining보다는 느리지만 훨씬 더 강력하고 유연합니다. 예를 들어 값이 일치하는 위치에 단순히 연결하는 것이 아니라, fuzzy text 일치 및 사용자 정의 표현에 기초하여 테이블을 결합할 수 있습니다. 사용자 지정 식에서는 사용자가 원하는 방식으로 테이블을 결합할 수 있습니다. |
| Stratify | 특정 칼럼을 계층화하여 그룹핑하여 별도의 하위 테이블의 목록으로 구분할 수 있습니다. 예를 들어 영업 거래 테이블을 각 영업 사원별로 별도의 테이블로 구분할 수 있습니다. |
| Summarize | 요약(Summarize)을 통해 합계, 평균, 표준 편차, 개수 등의 요약 기능을 사용하여 계층화된 테이블을 다시 조합할 수 있습니다. 요약(Summarize)은 해당 기간 동안 구매자당 총 구매액을 계산하거나, 가장 많이 사용되는 벤더를 찾는 데 유용합니다. 요약(Summarize)은 구조화된 쿼리 언어의 GROUPBy와 유사합니다. |
| Pivot Table | Excel의 피벗 테이블 기능과 유사한 기능을 제공합니다. |
| Upload Table To Database | Fraudit 테이블을 데이터베이스에 직접 업로드 시킬 수 있게 해줍니다. |
| 메뉴명 | 주요기능 |
|---|---|
| Descriptives | 테이블의 데이터 세트에 대하여 개수, 표준편차, 최대값, 최소값, 합계와 같은 기본적인 통계결과를 보여줍니다. |
| Benford Analysis | Benford 법칙을 사용하여 column 값이 자연스러운지 아닌지를 평가할 수 있습니다. 자세한 것은 Benford Analysis 장에서 설명하기로 합니다. |
| Digital Analysis | 분석이 필요한 칼럼에 대하여 아래와 같은 분석 칼럼을 옆에 추가한다. |
| Find |
|
| Outliers |
레코드 세트에서 이상 징후를 검색할 수 있습니다. |
| Trend |
|
| 메뉴명 | 주요기능 |
|---|---|
| Monetary Unit Sampling | 화폐단위 샘플링의 Plan(계획), Extract(샘플추출), Evaluation(샘플링 결과 평가) 기능을 제공합니다. |
| 메뉴명 | 주요기능 |
|---|---|
| Expression builder | 각종 수식 및 Fraudit 내장함수를 검색할 수 있으며 이를 통하여 새로운 산 식을 넣을 수 있는 기능입니다. |
| Journal Analysis | 각종 회계프로그램의 분개장을 토대로 8가지의 Journal Entry Test를 할 수 있으며, 현금흐름표(직접법)를 자동으로 작성해 주는 기능입니다. |
| Deep(Machine) Learning | 딥러닝, 머신러닝 기법을 사용할 수 있는 기능이다. 현재 버전에서는 XGBoost 기법과 Deep Neural Network 기능을 제공합니다. |
Fraudit의 Best Pratice
- Fraudit을 활용하려는 목적이 각각 다를 수 있지만 아래에서는 일반적인 Fraudit 사용자들에게 무엇이 가장 효과적인 방법인지에 대하여 설명하도록 하겠습니다.
- Fraudit을 사용하여 대규모 기업 데이터베이스를 데이터 마이닝한 후 부정적발에 대한 분석을 하는 경우가 많습니다. 이러한 데이터베이스는 대용량이고 상당한 양의 처리가 필요합니다.
데이터를 자주 수정하지 않는 경우가 대부분이라면 읽기 전용 데이터 소스로 보는 것도 좋은 방법입니다. - Fraudit을 활용하는 프로세스를 좀더 구체적으로 설명하면 다음과 같습니다.
① 첫 번째 단계는 데이터 웨어하우스를 만드는 것입니다.
Fraudit 테이블에 데이터를 조회하면 Fraudit의 Upload Table기능을 사용하여 데이터를 데이터 웨어하우스에 업로드할 수 있습니다.
MS Access를 사용하는 경우 액세스를 직접 사용하여 회사 서버에서 데이터 웨어하우스로 데이터를 조회할 수 있습니다.
③ 일단 데이터가 웨어하우스에 저장되면 원본 데이터 손상에 대해 걱정할 필요가 없습니다.
ODBC를 통해 Fraudit를 데이터 웨어하우스에 연결하고, 쿼리 및 Fraudit의 분석 루틴을 사용하여 분석을 완료하기만 하면 됩니다.
Fraudit는 강력한 프로그램이지만 다른 소프트웨어 패키지에는 나름의 고유한 기능이 있습니다. MS Excel 및 Crystal Reports와 같은 다른 프로그램도 유용할 수 있습니다
(하지만 Fraudit은 파이썬 베이스라는 것을 잊지마세요. 강력한 라이브러리는 얼마든지 인터넷에서 찾을 수 있습니다).
- 먼저 서버를 Setup해야 합니다. 이 서버는 PostgreSQL, MySQL, SQL서버 또는 기타 데이터베이스가 있는 시스템입니다. 특히, PostgreSQL과 MySQL은 무료이며, MySQL은 사용방법이 그리 어렵지 않습니다.
처음 사용자는 MS Access를 사용할 수 있습니다. - 수행하려는 분석 유형에 따라 필요에 맞게 데이터베이스를 설계합니다. 데이터베이스, 테이블 및 쿼리를 생성하는 방법을 데이터베이스 장에서 자세히 설명하도록 합니다.
Fraudit 테이블에 데이터를 조회하면 Fraudit의 Upload Table기능을 사용하여 데이터를 데이터 웨어하우스에 업로드할 수 있습니다.
MS Access를 사용하는 경우 액세스를 직접 사용하여 회사 서버에서 데이터 웨어하우스로 데이터를 조회할 수 있습니다.
③ 일단 데이터가 웨어하우스에 저장되면 원본 데이터 손상에 대해 걱정할 필요가 없습니다.
ODBC를 통해 Fraudit를 데이터 웨어하우스에 연결하고, 쿼리 및 Fraudit의 분석 루틴을 사용하여 분석을 완료하기만 하면 됩니다.
Fraudit는 강력한 프로그램이지만 다른 소프트웨어 패키지에는 나름의 고유한 기능이 있습니다. MS Excel 및 Crystal Reports와 같은 다른 프로그램도 유용할 수 있습니다
(하지만 Fraudit은 파이썬 베이스라는 것을 잊지마세요. 강력한 라이브러리는 얼마든지 인터넷에서 찾을 수 있습니다).
- 사실 실무적으로 감사인이 이러한 절차를 충실하게 지키기는 어려울 수 있습니다. 이때는 어쩔 수 없이 회사로부터 CSV 파일이나 text 파일을 받아서 이를 Fraudit에 Import하여 분석할 수 밖에 없습니다.
Fraudit의 주요 기능은 분석이라는 것을 다시 한번 이해하기 바랍니다.
Fraudit의 기능은 데이터 스토리지, 빠른 액세스 및 강력한 쿼리를 전문으로 하는 데이터베이스와 함께 사용될 때 가장 강력한 기능을 발휘합니다.
Fraudit의 Preferences
- 일반 기본 설정(General Preferences)을 사용하면 필요에 따라 Fraudit을 Customizing 할 수 있습니다.
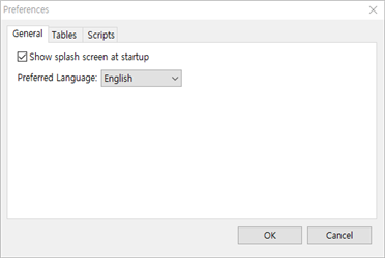
① Fraudit이 시작하면 프로그램이 로드되는 동안 스플래시 화면이 표시됩니다. 이를 체크하지 않으면 스플래시 화면이 보여지지 않습니다.
② Preferred Language : 영어와 한글 둘 중 하나를 선택합니다. 디폴트는 영어이며 현재 버전에서는 영어만 됩니다.
② Preferred Language : 영어와 한글 둘 중 하나를 선택합니다. 디폴트는 영어이며 현재 버전에서는 영어만 됩니다.
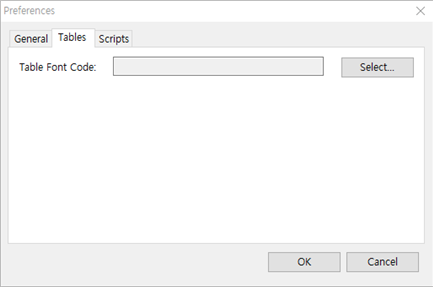
① Table Font를 선택할 수 있습니다.
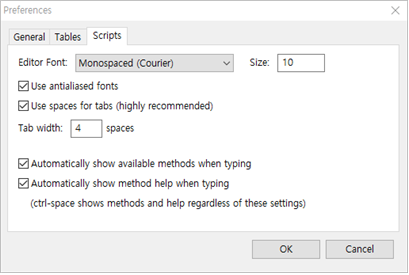
① 스크립트 에디터의 폰트를 수정할 수 있습니다.
② Tab 키를 누를 때마다 커서가 일정한 공간만큼 이동합니다. 이 숫자는 "탭 폭" 텍스트 상자에서 설정할 수 있습니다(파이썬 베이스이므로 가능한 4로 하기 바랍니다).
③ Typing이 끝나면 Fraudit 또는 Python의 방법 예를 자동으로 보여지게 체크할 수 있습니다.
④ Typing 도중에 방법과 help를 자동으로 보여지게 할 수 있습니다.
이러한 기능은 보다 효과적이고 정확하게 script를 작성하는데 도움이 됩니다. 원하는 경우 이러한 기능을 사용하지 않도록 설정할 수 있습니다.
② Tab 키를 누를 때마다 커서가 일정한 공간만큼 이동합니다. 이 숫자는 "탭 폭" 텍스트 상자에서 설정할 수 있습니다(파이썬 베이스이므로 가능한 4로 하기 바랍니다).
③ Typing이 끝나면 Fraudit 또는 Python의 방법 예를 자동으로 보여지게 체크할 수 있습니다.
④ Typing 도중에 방법과 help를 자동으로 보여지게 할 수 있습니다.
이러한 기능은 보다 효과적이고 정확하게 script를 작성하는데 도움이 됩니다. 원하는 경우 이러한 기능을 사용하지 않도록 설정할 수 있습니다.
Fraudit의 Table
- 이 장에서는 Fraudit의 기본 데이터 구조인 Table에 대해서 설명하기로 합니다.
Fraudit은 모든 기능과 루틴이 데이터 Table에서 작동하기 때문에 먼저 Table을 이해해야 합니다. Table은 MS Excel과 같은 스프레드시트와 매우 유사하며, column과 row로 이루어진 2차원 그리드입니다.
Fraudit의 Table 개요
- Fraudit의 Table은 데이터의 2차원 그리드입니다. 데이터는 모든 종류가 될 수 있으며, Table의 모든 셀이 동일할 필요는 없습니다.
몇 가지 예외를 제외하고 Fraudit에 있는 거의 모든 기능과 루틴은 Table을 가정하고 입력 및 출력을 하기 때문에 데이터를 Table에 보관해야 할 필요가 있습니다. - 어떤 점에서는 Table을 MS Excel과 같은 스프레드시트로 생각할 수 있습니다. Fraudit은 데이터 입력 응용 프로그램이 아닌 기본 분석 응용 프로그램이기 때문에 Excel, 액세스 또는 유사한 데이터 원본을 Fraudit에 가져오는 경우가 많습니다.
하지만, Fraudit Table은 스프레드시트와 다음과 같은 몇 가지 중요한 차이점이 있습니다. - Fraudit Table의 각 row(record라고도 함)은 일반적으로 금액, 명칭 또는 날짜와 실제 세계의 정보를 나타냅니다. 각 record는 개별 항목입니다. 만약 20개의 영화에 대한 정보를 저장하고 싶다면, 테이블에는 20개의 record가 있을 것입니다.
- Fraudit Table의 column(field라고도 함)은 항상 이름이 지정되어 있고 대개 같은 유형의 데이터를 포함합니다. Table에 영화에 대한 정보가 있는 경우 첫번째 column은 영화 제목, 두번째 column은 개봉연도 등이 될 수 있습니다.
column 이름은 스프레드시트처럼 테이블에 기록되지 않으며 A', 'B', 'C' 등과 같이 column의 제목으로 바꿀 수 있습니다. - Fraudit Table에는 데이터를 저장한 만큼의 열과 행만 있게 됩니다. 반면 MS Excel과 같은 스프레드시트에는 항상 104만개(과거 버전은 6만 5천개)의 행과 A-XFD열(과거 버전은 IV)이 있습니다.
Fraudit Table에 다른 레코드를 추가하려면, 먼저 그 끝에 새 행을 추가해야 합니다. - 일반적으로 Fraudit Table에는 제한된 산식을 가지는 대량의 데이터가 들어갑니다. MS Excel과 같은 스프레드시트는 셀 단위의 계산을 전문으로 하며, 흔히 대출 원리금 상환 또는 세금 계산 등과 같은 같은 작업에 사용됩니다.
이와는 대조적으로, Fraudit의 계산은 일반적으로 셀 단위보다 전체 column에 대해 이루어집니다. - 큰 테이블로 작업해야 하는 경우(수억개에서 수십억개에 이르는 레코드 범위), 운영 데이터베이스에 레코드를 저장할 필요가 있습니다.
왜냐하면 Fraudit의 데이터베이스 모듈은 전체 테이블을 메모리에 한번에 로딩하지 않고 개별적으로 레코드를 통해 반복할 수 있기 때문입니다. - 각 Fraudit Table은 이론적으로 21억 row과 21억 column을 수용할 수 있지만, 대부분의 사용자는 이 이론적 한계에 도달하지 못할 것입니다. Fraudit의 테이블 크기에 대한 기본 제한은 컴퓨터 메모리입니다.
row과 column의 숫자에 대한 현실적인 한계는 각 셀의 데이터 크기와 열과 행의 비율에 따라 달라집니다. - Table은 항상 Fraudit에서 명명된다. Table을 load하거나 만들 때 Fraudit는 대화 상자, 루틴 및 기타 작업에 참조할 수 있는 이름을 입력하도록 합니다.
이 이름은 일반적으로 데이터가 로드된 파일 이름과 비슷하지만 원하는 이름으로 얼마든지 변경할 수 있습니다. - Table에서 스크립팅 기능을 사용하기 위해서는 Table(및 column)이름 형식에 몇 가지 제한이 있습니다. Table 이름은 A, b또는 z와 같은 알파벳 문자로 시작해야 합니다. 이름의 나머지 문자는 임의의 문자, 숫자 또는 밑줄(underbar)이 될 수 있습니다.
Table 이름은 대문자와 소문자를 구분하기 때문에 MyTable은 Mytable과 다른 Table을 의미합니다. - 다음은 유효한 Table 이름의 예입니다.
- mytable
- MyTable
- emp records
- emp records15
- weather12data
- 다음은 유효하지 않은 Table 이름의 예이다.
- 7eleven (starts with a number)
- ydate/6 (includes a slash)
- Dark Woods (includes a space)
- 상기의 명명 규칙은 column 이름에도 적용된다.
Loading and Saving Fraudit Files
- Fraudit의 “.tbl” 기본 형식은 Table을 디스크에 저장하는 cross-platform 파일 형식입니다. 이 형식은 Fraudit에서만 읽을 수 있지만, column 이름과 유형, 셀 데이터 및 column 계산을 포함하여 테이블과 관련된 모든 정보를 저장합니다.
Fraudit for Windows에 저장된 파일은 Fraudit for Mac 또는 Fraudit for Linux에 열거나 그 반대로 열 수 있습니다. - Fraudit에 데이터를 저장하는 가장 좋은 방법은 데이터베이스를 같이 사용하는 것입니다. 일반적으로 데이터베이스는 어떤 데스크탑 제품도 따라올 수 없는 데이터 보안, 검색 및 색인과 같은 기능을 제공합니다.
Fraudit과 함께 중요한 작업을 하는 경우 이러한 데이터베이스 중 하나를 사용하여 데이터 웨어하우스를 설정하는 것이 효과적일수 있습니다(오픈 소스 데이터베이스도 좋은 방법입니다). - 그렇다면 왜 Fraudit의 “.tbl” 이 필요한가? 데이터베이스 및 데이터 웨어하우스는 설정 및 유지 관리가 어려울 수 있으며, 이러한 데이터베이스는 소규모 프로젝트에 너무 과할 수 있기 때문입니다
(몇 천개의 record를 위해서 굳이 데이터베이스를 구축하는 것은 비효율적입니다).
이렇게 작은 상황에서는 Fraudit의 “.tbl”이 매우 효율적입니다. “.tbl” 파일은 크기에 상관없이 테이블을 보관할 수 있지만, 더 작은 테이블에 특히 효율적입니다. - cross-platform이고 Fraudit에 네이티브인 것 이외에도 “.tbl” 파일은 디스크 공간을 절약하도록 자동으로 압축됩니다. 즉, “.tbl” 파일을 굳이 압축해서 이메일로 보내거나 다른 방법으로 다른 사람에게 보내지 않아도 됩니다.
Fraudit의 데이터 형식
데이터 타입(Type)
- Fraudit에서 지원하는 데이터 타입(Type)은 아래와 같이 6가지입니다.
【표 1 】Fraudit에서 지원하는 데이터 타입(Type)
| Type | 예 |
|---|---|
| String | 직원 이름과 같은 일련의 텍스트 문자 (예: "홍길동") |
| Integer | 4 또는 -22와 같은 정수(소수 점 이하는 될 수 없지만 음수일 수 있음) |
| Decimal Number | 28.9047과 같이 소수 점 이하인 숫자 |
| Date Time | 특정 날짜 및 시간 |
| True/False | 속성이 true 또는 false인 경우 사용 |
DateTime
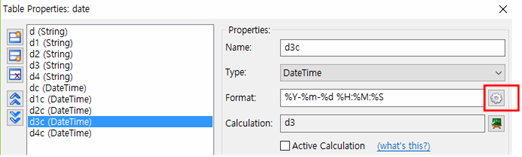
Table Properties로 String을 DateTime으로 변환하기
- 실제 CSV나 MS Excel 파일을 import할 때 가장 에러가 많이 발생하는 경우가 바로 Date Time의 타입입니다.
- Fraudit에서는 약간의 처리과정을 통하여 String을 DateTime의 타입으로 변경할 수 있습니다.
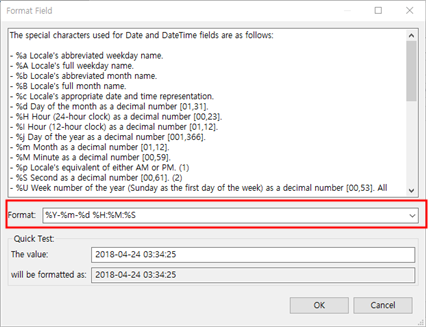
- Format에 직접 상기와 같이 기입하여 변경할 수 있으며 Format Field에 들어가서 드롭다운 리스트로 선택할 수도 있습니다.
| String | Type 변환 | Format |
|---|---|---|
| YYYY-MM-DD | DateTime | %Y-%m-%d |
| YYYY/MM/DD | DateTime | %Y/%m/%d |
| MM-DD-YYYY | DateTime | %Y%m%d |
| MM-DD-YYYY | DateTime | %m-%d-%Y |
DateTime 형식간 산식
- DateTime 형식을 가지는 2개의 value 또는 1개의 value와 integer 간의 산식은 다음과 같이 요약할 수 있습니다.
【표 22】Fraudit에서 지원하는 DateTime 간 산식 지원
| date1 | date2 | 산식 | 결과 |
|---|---|---|---|
| DateTime | DateTime | String | |
| 2018-03-04 23:00:00 | 2018-03-01 00:00:00 | date1 – date2 | 3 days, 23:00:00 |
| 2018-03-01 00:00:00 | 2018-03-04 00:00:00 | date1 – date2 | 주1) -4 days, 1:00:00 |
주1) 언뜻 보면 이해가 안갈 수 있지만 이 결과의 의미는 –4 days에서 1시간을 뺀다는 의미로 실질적으로는 –3 days, 23:00:00을 의미하는 것입니다.
| date1 | d3 | 산식 | 결과 |
|---|---|---|---|
| DateTime | Integer | DateTime | |
| 2018-03-04 23:00:00 | 1 | date1 + d3 | 2018-03-05 23:00:00 |
| 2018-03-01 00:00:00 | 1 | date1 + d3 | 2018-03-02 00:00:00 |
DateTime을 숫자로 변환하기
- 입찰 부정등과 같이 입찰일자의 분포를 분석하기 위해서는 날짜를 숫자로 변환해야 하는 경우가 발생할 수 있습니다. Fraudit에서는 DateToNum(DateTime형식의 칼럼명) 함수를 이용하면 쉽게 날짜를 숫자로 변환할 수 있습니다.
| date1 | 계산칼럼 | 결과 |
|---|---|---|
| DateTime | Integer | |
| 2018-12-01 | DateToNum(date1) | 1543590000 |
숫자를 DateTime으로 변환하기
| date1 | 계산칼럼 | 결과 |
|---|---|---|
| Integer | DateTime | |
| 1543590000 | NumToDate(date1) | 2018-12-01 |
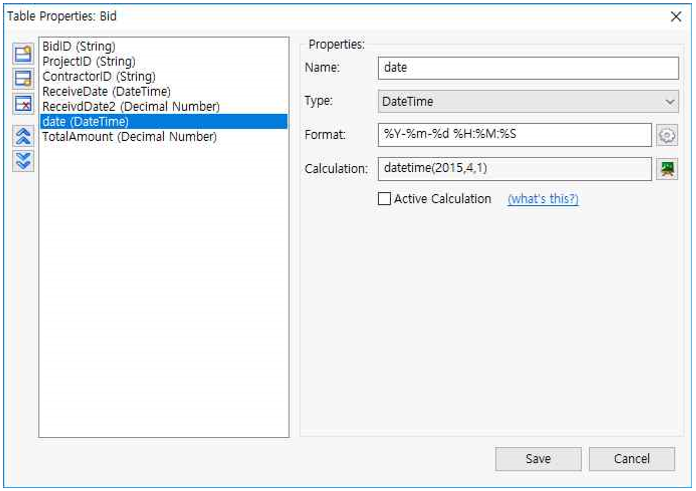
특정일을 DateTime으로 입력하기
- 파이썬의 기본 함수인 datetime을 이용하여 날짜를 직접 입력 할 수 있습니다.
date를 나타내는 칼럼을 삽입합니다.
Type : DateTime 선택
Format : %Y-%m-%d 선택
Calculation : datetime(YYYY, MM, DD)
Save 버튼을 선택 합니다.
☞스크립트 쉘에서는 datetime.datetime(YYYY, MM, DD) 로 입력해야만 하지만 Expression Builder에서는 이미 Type에서 datetime을 불러 왔기 때문에 상기와 같이 datetime (YYYY, MM, DD)로 해야 합니다.
Type : DateTime 선택
Format : %Y-%m-%d 선택
Calculation : datetime(YYYY, MM, DD)
Save 버튼을 선택 합니다.
☞스크립트 쉘에서는 datetime.datetime(YYYY, MM, DD) 로 입력해야만 하지만 Expression Builder에서는 이미 Type에서 datetime을 불러 왔기 때문에 상기와 같이 datetime (YYYY, MM, DD)로 해야 합니다.
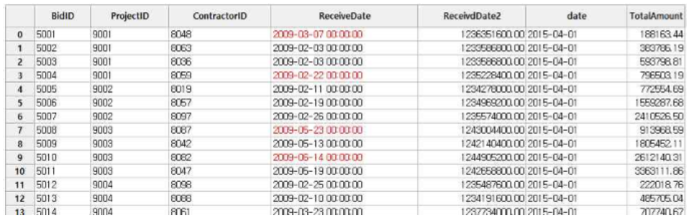
특정일자가 DateTime 형식으로 입력되는 것을 확인할 수 있습니다.
Fraudit의 기본 메뉴 활용
- 이 장에서는 사례 파일을 가지고 Fraudit의 기본 메뉴가 어떤 기능을 수행하는지를 살펴봅니다. 사례 파일은 기본 예제파일인 “Bid.tbl”입니다.
- tbl파일열기
- Table Sorting
- 레코드추가 또는 삭제
- 테이블 데이터의 복사 및 붙여넣기
- 데이터 불러오기
- 테이블 닫기
- 칼럼(field)과 레코드(row)
- 칼럼(field) 삽입 및 삭제
- 필터링(Filtering)
tbl 파일 열기
- “Bid.tbl”을 여는 방법은 아래 2가지 방법입니다.
- File >> Open으로 열거나,
- 네비게이터에서 해당 “Bid.tbl”을 더블클릭합니다.
Table Sorting
- Sorting을 사용하면 Fraudit Table을 정렬하여 column에 높은 값 또는 낮은 값을 강조할 수 있습니다.
- Table을 정렬하기 전에 오름차순과 내림차순 간의 차이점을 이해하는 것이 중요합니다. 오름차순은 가장 낮은 숫자 또는 첫번째 문자를 배열하여 정렬합니다(예: ABC.. ). 내림차순은 가장 큰 숫자 또는 마지막 문자(예: ZYX...)가 배치됩니다.
column에 숫자와 문자가 모두 포함되어 있는 경우 오름차순은 숫자가 문자 앞에 오며 (예:123ABC..), 내림차순은 문자가 숫자앞에 옵니다(예: ZYX987..) - Table을 Sorting하는 방법은 다음과 같이 크게 2가지로 구분됩니다.
- Table을 정렬할 때는 정렬하려는 column의 데이터 유형에 주의를 기울여야 합니다. Integers, Decimal, Datetime, string은 매우 다르게 분류됩니다.
예를 들어, “4,12,22,165”와 같은 Integer는 오름차순 모드로 정렬됩니다. 그러나 하지만 이러한 값이 Integer가 아닌 string으로 입력되면 개별 문자가 숫자가 아닌 텍스트로 표시됩니다.
따라서 이 시퀀스는 '12','165','22','4'로 나뉘게 됩니다. column 형식에 대한 자세한 내용은 데이터 형식에 대한 장을 참조하기 바랍니다.
【File 메뉴의 Sort 메뉴을 이용하는 방법】
① File >> Sort를 누릅니다.
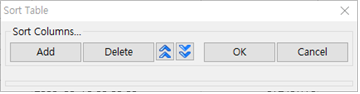
② Add 버튼을 누르면 column이 추가되며 order에서 Ascending 과 Descending을 선택할 수 있습니다.
③삭제하기 위한 column에 체크박스를 선택하고 Delete 버튼을 누르면 해당 column이 삭제됩니다.
☞ 여기서는 BidID 칼럼과 ContractorID 칼럼을 추가하고 둘다 오름차순으로 정렬하기로 합니다.
③삭제하기 위한 column에 체크박스를 선택하고 Delete 버튼을 누르면 해당 column이 삭제됩니다.
☞ 여기서는 BidID 칼럼과 ContractorID 칼럼을 추가하고 둘다 오름차순으로 정렬하기로 합니다.
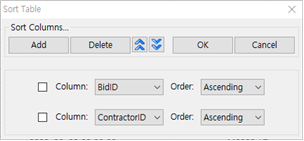
④ 정렬 조건의 순서를 변경하기 위해서는 column에 체크박스를 선택하고 위 아래 이동 버튼을 눌러 column 순서를 변경합니다.
⑤ OK버튼을 누르면 Sorting이 실행됩니다.
⑤ OK버튼을 누르면 Sorting이 실행됩니다.
【테이블의 칼럼에서 오른쪽 클릭으로 Sort하는 방법】
① Sort하고자 하는 칼럼을 선택하고 오른쪽 클릭을 한 후 오름차순과 내림차순 중 하나를 선택합니다.
☞ 이 방법은 하나의 칼럼에 대해서만 Sort할 수 있으며 여러개의 칼럼에 대해서 Sort 조건을 정하기 위해서는 File 메뉴의 Sort 메뉴를 이용하여야 합니다.
☞ 이 방법은 하나의 칼럼에 대해서만 Sort할 수 있으며 여러개의 칼럼에 대해서 Sort 조건을 정하기 위해서는 File 메뉴의 Sort 메뉴를 이용하여야 합니다.
레코드 추가 또는 삭제
- Fraudit은 데이터 입력 응용 프로그램이 아니지만 사용자가 직접 데이터를 수정하고 레코드를 추가 또는 제거할 수 있습니다.
셀의 데이터를 편집하기 위해서는, 그것을 더블 클릭하거나 단순히 셀에 타이핑을 시작하면 됩니다. - Table에 레코드를 추가하는 방법은 다음과 같습니다.
- 새 row의 각 셀에는 N 으로 표시되는 None 값이 주어집니다. 이 값은 데이터가 없음을 나타냅니다(0이나 화면에 아무것도 안보이는 것과 다른 의미입니다).
이 값에 대한 자세한 내용은 데이터 형식에 대한 장을 참조하기 바랍니다. - 다음은 row를 삭제하는 것입니다. 아마도 row를 만든 후에, 갑자기 새로운 row가 필요하지 않다는 것을 깨달을 수 있습니다. 기존 레코드를 삭제하는 것은 오른쪽 클릭을 한 후 "Delete" 옵션을 선택하면 됩니다.
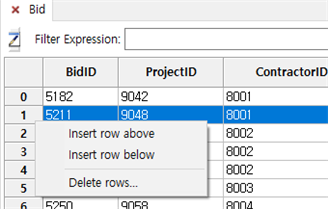
① Row를 선택하고 그 위에 삽입할지, 그 아래에 삽입할지를 선택합니다.
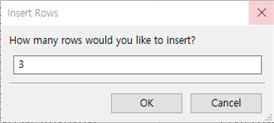
② 삽입하고자 하는 Row의 개수를 설정한다. 여기서는 3개만 입력하기로 하고 3을 입력합니다.
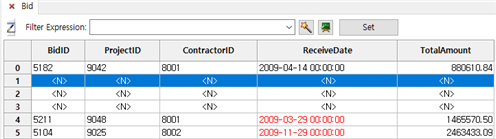
③ 위로 3개의 Row가 삽입되는 것을 확인할 수 있습니다.
테이블 데이터의 복사 및 붙여넣기
- Table의 데이터는 일반적인 방법으로 복사하여 붙여 넣을 수 있습니다.
MS Excel과 같은 어플리케이션에서 셀을 선택하여 클립 보드에 복사하고 Fraudit의 빈 테이블에 붙여 넣을 수 있습니다. 마찬가지로, Fraudit의 셀을 복사해서 다른 애플리케이션으로 붙여 넣을 수 있습니다. - Fraudit에 데이터를 붙여 넣을 때는 현재 선택된 셀에 붙여 넣기가 시작됩니다. 전체 값 테이블을 붙여 넣으려면 커서가 왼쪽 위 셀에 있어야 합니다.
Fraudit은 붙여 넣은 데이터에 필요한 레코드를 자동으로 추가합니다. 그러나 Table에 column이 자동으로 추가되지는 않습니다.
데이터 불러오기
- 데이터를 Fraudit에 가져오는 방법은 몇가지가 있습니다. 이러한 방법은 본 장의 범위를 벗어나지만 간략하게 소개하면 다음과 같습니다.
- 데이터 가져오기 마법사를 사용하여 Excel 파일을 Fraudit에 가져오는 방법
- 데이터 가져오기 마법사를 사용하여 텍스트 파일(예: csv)을 가져오는 방법
- 데이터베이스에 대한 ODBC 연결 후 Table을 Fraudit에서 조회하는 방법
- 상기 방법 중 Excel, CSV 파일을 데이터 가져오기 마법사를 사용하여 가져오는 방법을 설명하도록 하겠습니다.
- 상기와 같이 Fraudit 테이블로 불러온 결과가 나타납니다.
【Excel 파일 불러오기】
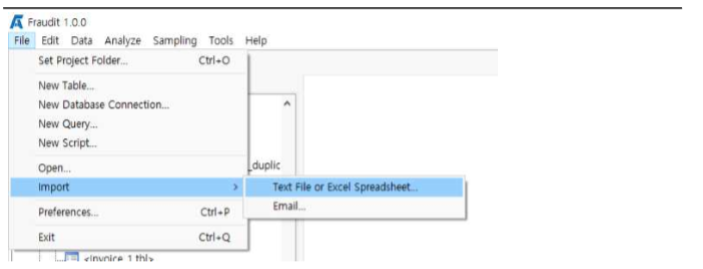
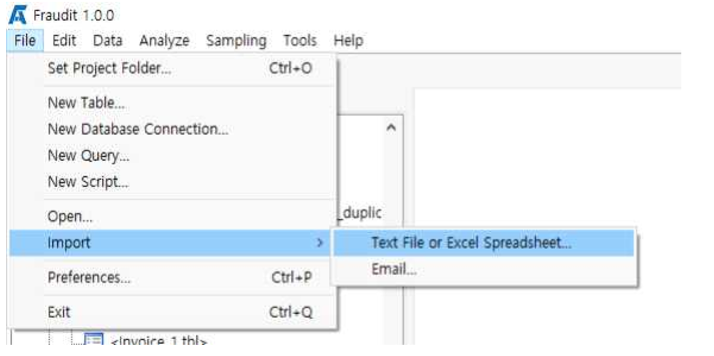
File >> Import >> Text File or Excel Spreadsheet 메뉴를 클릭 합니다.
Select 버튼을 클릭 합니다.
예제파일 중 baseball.xlsx 파일을 선택하고 불러옵니다.
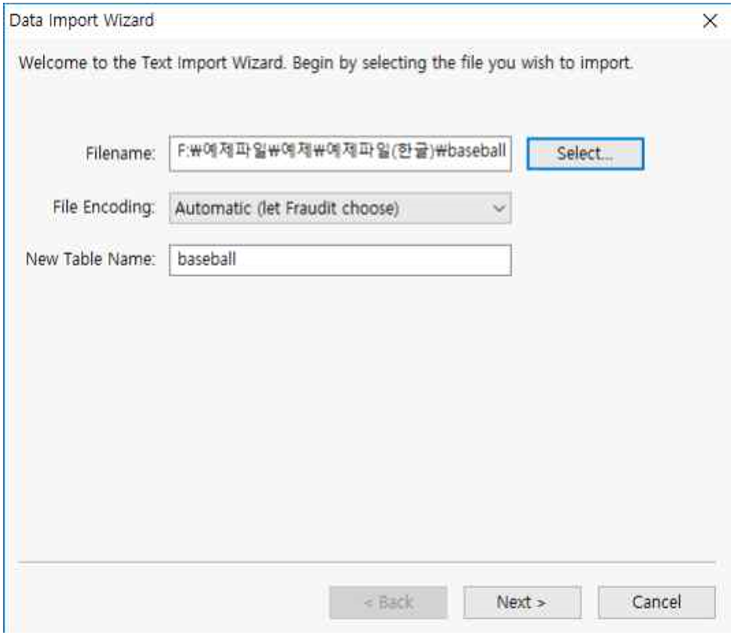
① 원본 데이터에 한글이 포함되어 있는 경우 (헤더 및 데이터 중 한글자라도 한글이 포함된 경우) File Encoding을 Korean(cp949, 949, ms949, uhc)로 선택합니다. 여기서는 한글이 포함 되어 있지 않기 때문에 File Encoding을 Automatic으로 선택합니다.
② New Table Name을 baseball로 합니다.
② New Table Name을 baseball로 합니다.
File Type을 Microsoft Excel File으로 선택한 후 Next 버튼을 누릅니다.
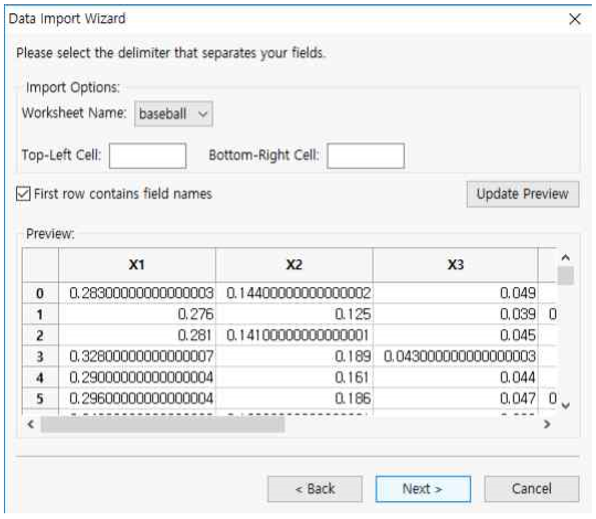
① Worksheet Name : 엑셀 시트가 여러개인 경우 불러오고 싶은 시트명을 드롭다운 리스트에서 선택합니다. 여기서는 baseball 하나의 시트만 있으므로 이를 선택합니다.
② Top-Left Cell은 불러올 영역 중 가장 왼쪽 상단을 의미하며 해당 셀값을 입력하면 됩니다. 여기서는 공란으로 남깁니다.
③ Bottom-Right Cell은 불러올 영역 중 가장 오른쪽 하단을 의미하며 해당 셀값을 입력하면 됩니다. 여기서는 공란으로 남깁니다.
④ First row contains filed names를 체크하면 첫번째 row를 필드명으로 자동 변환해줍니다.
⑤ update Preview는 Worksheet Name을 변경하는 경우 반드시 눌러야 하며 그 결과는 Preview에서 업데이트 됩니다. 여기서는 누르지 않습니다.
⑥ Next 버튼을 누릅니다.
② Top-Left Cell은 불러올 영역 중 가장 왼쪽 상단을 의미하며 해당 셀값을 입력하면 됩니다. 여기서는 공란으로 남깁니다.
③ Bottom-Right Cell은 불러올 영역 중 가장 오른쪽 하단을 의미하며 해당 셀값을 입력하면 됩니다. 여기서는 공란으로 남깁니다.
④ First row contains filed names를 체크하면 첫번째 row를 필드명으로 자동 변환해줍니다.
⑤ update Preview는 Worksheet Name을 변경하는 경우 반드시 눌러야 하며 그 결과는 Preview에서 업데이트 됩니다. 여기서는 누르지 않습니다.
⑥ Next 버튼을 누릅니다.
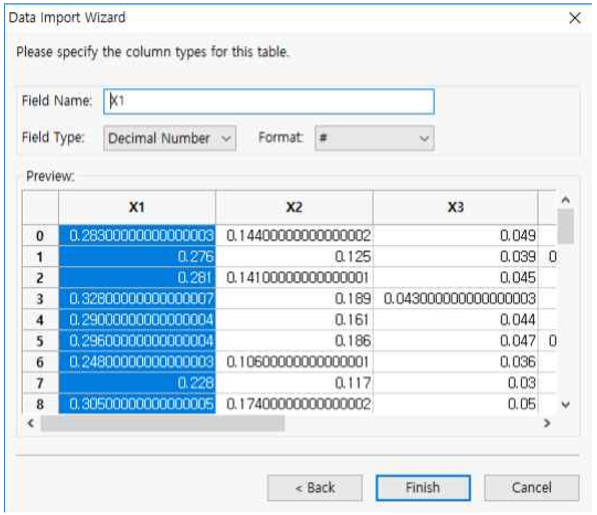
① Preview의 칼럼을 선택하면 Field Name이 자동으로 해당 칼럼명을 나타냅니다. 만약 이를 바꾸고 싶으면 직접 입력하면 된다.
② Field Type과 Format을 적절하게 선택할 수 있습니다. 여기서는 디폴트 선택사항으로 하고 Finish 버튼을 누릅니다.
② Field Type과 Format을 적절하게 선택할 수 있습니다. 여기서는 디폴트 선택사항으로 하고 Finish 버튼을 누릅니다.
【CSV 파일 불러오기】
File >> Import >> Text File or Excel Spreadsheet 메뉴를 클릭 합니다.
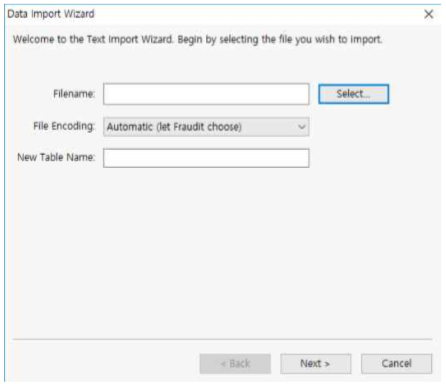
Select 버튼을 클릭 합니다.
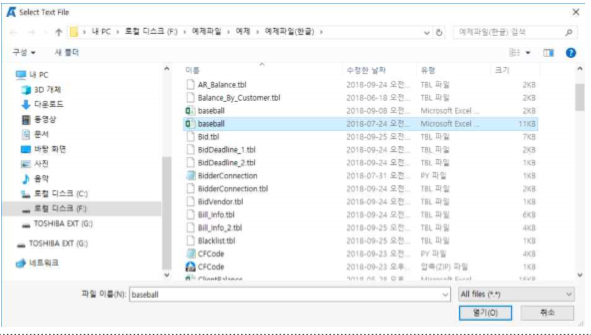
예제파일 중 baseball.csv 파일을 선택하고 불러옵니다.
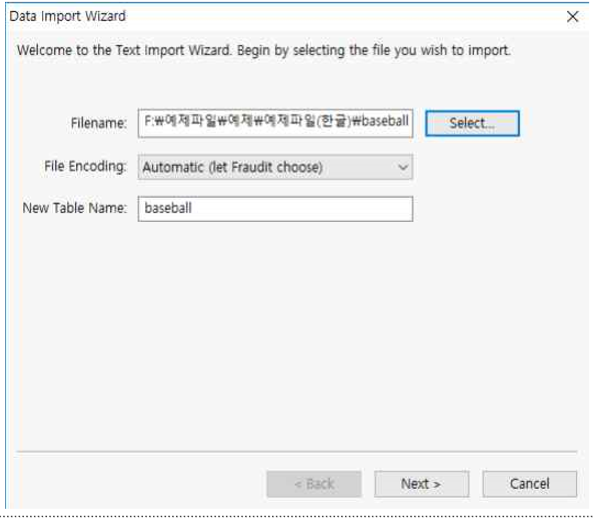
① 원본 데이터에 한글이 포함되어 있는 경우 (헤더 및 데이터 중 한글자라도 한글이 포함된 경우) File Encoding을 Korean(cp949, 949, ms949, uhc)로 선택합니다. 여기서는 한글이 포함 되어 있지 않기 때문에 File Encoding을 Automatic으로 선택합니다.
② New Table Name을 baseball로 합니다.
② New Table Name을 baseball로 합니다.
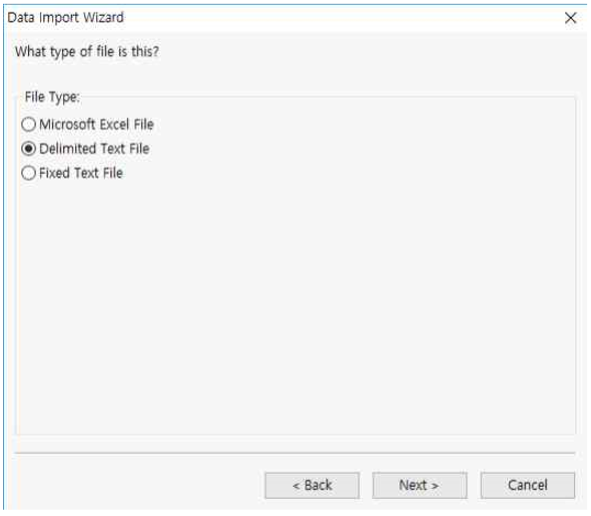
File Type을 Delimited Text File으로 선택한 후 Next 버튼을 누릅니다.
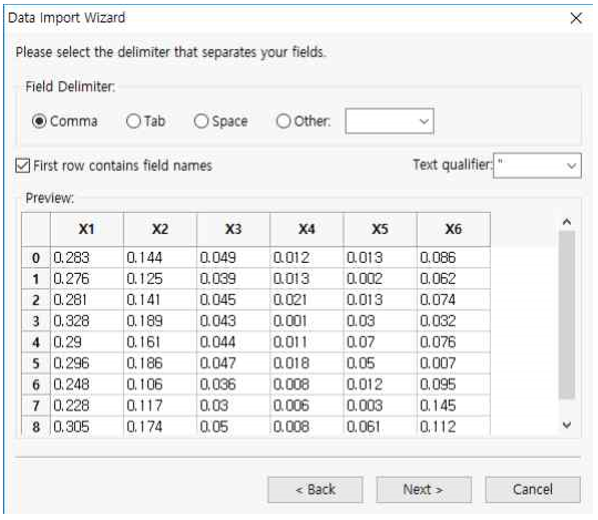
① Field Delimiter : Comma를 선택합니다.
② First row contains filed names를 체크하면 첫번째 row를 필드명으로 자동 변환해줍니다.
③ Next 버튼을 누릅니다.
② First row contains filed names를 체크하면 첫번째 row를 필드명으로 자동 변환해줍니다.
③ Next 버튼을 누릅니다.
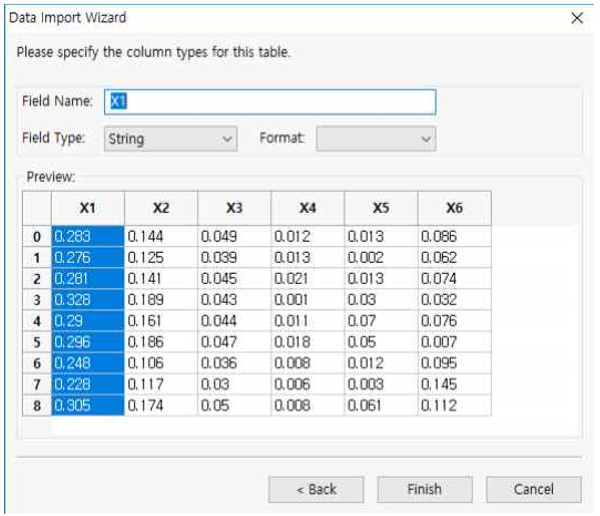
① Preview의 칼럼을 선택하면 Field Name이 자동으로 해당 칼럼명을 표시 합니다. 만약 이를 바꾸고 싶으면 직접 입력 하시기 바랍니다.
② Field Type과 Format을 적절하게 선택할 수 있습니다. 여기서는 디폴트 선택사항으로 하고 Finish 버튼을 누릅니다.
② Field Type과 Format을 적절하게 선택할 수 있습니다. 여기서는 디폴트 선택사항으로 하고 Finish 버튼을 누릅니다.
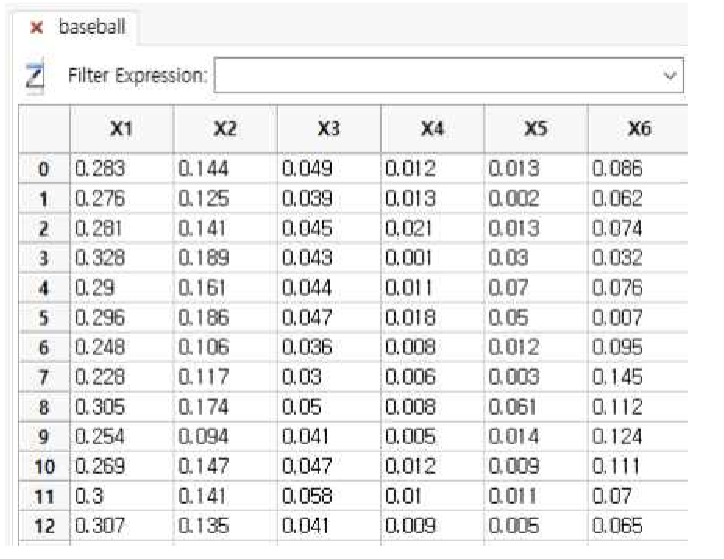
상기와 같이 Fraudit 테이블로 불러온 결과가 나타납니다.
테이블 닫기
- Fraudit 테이블은 영구성 정도에 따라 여러 가지로 닫을 수 있습니다. 이러한 내용은 다음과 같습니다.
- Close Table :
인터페이스에 Table이 표시되면 ① 파일 메뉴에서 Close Table을 누르거나 ② 테이블의 이름 탭에서 '탭 닫기' 아이콘(X표시)을 클릭합니다.
이 옵션들은 테이블을 보지 않도록 숨기기만 하여 테이블 데이터를 메모리에 남겨두고 왼쪽 Table 네비게이터에 이름을 남겨둡니다.
테이블을 다시 로드하려면 Table 네비게이터에서 해당 테이블을 두번 클릭하거나 Open 메뉴를 이용하여 테이블을 불러오면 됩니다. - Delete Table :
이 방법을 사용하면 테이블이 메모리 및 디스크에서 영구적으로 사라지게 됩니다. 따라서, 백업 디스크와 같은 다른 테이블의 복사본이 없으면 테이블이 영구적으로 없어지 게 되므로 유의하여야 합니다.
칼럼(field)과 레코드(row)
- Fraudit Table을 면밀하게 보면 스프레드시트와 매우 비슷하다는 것을 알 수 있게 됩니다. Table은 데이터의 2차원 그리드입니다. 스프레드시트와 마찬가지로 Fraudit Table의 column과 row는 다른 값들을 나타냅니다. row은 종종 레코드라고 불리고 사람, 장소 또는 물건 등을 나타냅니다.
예를 들어 ABC라는 회사에 500명의 직원이 근무하는 경우 Fraudit Table에 500개의 row 또는 레코드가 있으며, 각 row는 한명의 직원만을 나타냅니다. - 반면에, column은 사람, 장소 또는 물건을 나타내는 것이 아니라, 각각의 특정한 사람들의 장소나 물건에 대한 속성을 나타내는 것입니다.
이러한 column에는 각 row(또는 레코드)에 대해 일반화될 수 있는 특성이 정의되어 있습니다. 상기 ABC사에서, 모든 직원들이 공유하는 몇가지 일반적인 특성을 가정해봅시다.
이름, 입사일자, 생년월일, 부서, 직원 ID번호 등이 표시될 수 있습니다. 이러한 특정 속성은 특정 직원에 국한된 것이 아니라 모든 직원에 대해 일반적으로 적용되는 것입니다.
즉, 모든 직원은 이름, 입사일자 등이 있기 때문이다. 이러한 이유로 열을 흔히 필드라고 합니다.
칼럼(field) 삽입 및 삭제
- Fraudit Table에 필드 삽입 및 삭제 작업은 row의 삽입 및 삭제에 비하면 약간 복잡하게 느낄 수 있습니다. 하지만 그래도 사용자가 편하게 할 수 있는 인터페이스를 제공하고 있습니다.
각 필드는 테이블의 각 개별 레코드와 관련된 특정 속성을 정의하기 때문에 필드에는 데이터 형식을 지정해야 합니다. - 속성에 대한 데이터 형식을 지정하면 올바른 종류의 데이터가 속성 필드에 입력되도록 할 수 있습니다.
예를 들어 Fraudit 사용자가 실수로 직원 이름을 포함해야 하는 필드에 숫자를 입력할 수 있기 때문에 데이터 입력 오류 위험을 줄이기 위하여 데이터 형식은 각 필드(또는 열)생성시 정의됩니다. - 이러한 데이터 형식의 목록과 각 데이터 형식에 대한 간략한 설명은 아래와 같습니다.
- String : 직원 이름과 같은 일련의 텍스트 문자(예:"홍길동")
- Integer : 4 또는 -22와 같은 정수(소수 점 이하는 될 수 없지만 음수일 수 있음)
- Decimal Number : 28.9047과 같이 소수 점 이하인 숫자
- Date Time : 특정 날짜 및 시간
- True/False : 속성이 true 또는 false인 경우 사용
- 새로운 column을 삽입하고 데이터 형식을 선언하기 위해서는, “Table Properties” 인터페이스로 이동하여야 합니다. “Table Properties” 인터페이스에 접근하는 방법은 다음과 같이 두 가지가 있습니다.
- 특정 칼럼을 선택하고 오른쪽 클릭을 한후 Table Properties 메뉴를 선택하는 방법
- File 메뉴에서 Properties 메뉴를 선택하는 방법
- "Table Properties" 인터페이스가 표시되면 특정 column을 삽입 및 삭제하는 옵션을 사용할 수 있습니다.
- 새 column이 생성되면 데이터 형식을 지정해야 하는데 기본적으로 "String" 데이터 형식이 지정되기 때문에 이 형식을 적절하게 조정할 필요가 있습니다.
또한 "Decimal Number" 데이터 형식을 선택하면 해당 소수 점 숫자의 정밀도를 지정할 수 있습니다(예:소수 점 2개만 표시 등). - 한편 유의하여야 할점은 Table Properties를 저장하기 위해서는 반드시 Save 버튼을 눌러야 한다는 것이다. Save 버튼을 누르지 않고 나오면 변경내용이 저장되지 않습니다.
- 마지막으로, "Table Properties" 창에서 "Save" 버튼을 눌러도 실제 테이블을 저장하지 않고 Fraudit을 닫는 경우 파일 변경사항이 저장되지 않아 "Table Properties" 변경사항이 사라지게 됨에 유의하기 바랍니다.
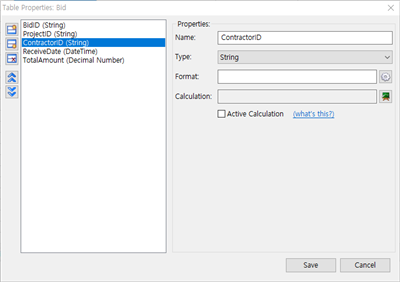
①  아이콘을 클릭하면 현재 필드(칼럼) 앞에 새로운 필드(칼럼)를 삽입하면서 Name, Type, Format, Calculation을 세팅할 수 있게 됩니다.
아이콘을 클릭하면 현재 필드(칼럼) 앞에 새로운 필드(칼럼)를 삽입하면서 Name, Type, Format, Calculation을 세팅할 수 있게 됩니다.
② 아이콘을 클릭하면 현재 필드(칼럼) 뒤에 새로운 필드(칼럼)를 삽입하면서 Name, Type, Format, Calculation을 세팅할 수 있게 됩니다.
아이콘을 클릭하면 현재 필드(칼럼) 뒤에 새로운 필드(칼럼)를 삽입하면서 Name, Type, Format, Calculation을 세팅할 수 있게 됩니다.
③ 아이콘을 클릭하면 현재 필드(칼럼)을 삭제합니다.
아이콘을 클릭하면 현재 필드(칼럼)을 삭제합니다.
④ 아이콘을 클릭하면 현재 필드(칼럼)가 앞으로 이동합니다.
아이콘을 클릭하면 현재 필드(칼럼)가 앞으로 이동합니다.
⑤ 아이콘을 클릭하면 현재 필드(칼럼)가 뒤로 이동합니다.
아이콘을 클릭하면 현재 필드(칼럼)가 뒤로 이동합니다.
아이콘을 클릭하면 현재 필드(칼럼) 앞에 새로운 필드(칼럼)를 삽입하면서 Name, Type, Format, Calculation을 세팅할 수 있게 됩니다. ②
아이콘을 클릭하면 현재 필드(칼럼) 뒤에 새로운 필드(칼럼)를 삽입하면서 Name, Type, Format, Calculation을 세팅할 수 있게 됩니다. ③
아이콘을 클릭하면 현재 필드(칼럼)을 삭제합니다.④
아이콘을 클릭하면 현재 필드(칼럼)가 앞으로 이동합니다.⑤
아이콘을 클릭하면 현재 필드(칼럼)가 뒤로 이동합니다.필터링(Filtering)
- 필터링은 Table에 있는 데이터를 분석하기 위한 필수적인 기능입니다. 필터링은 분석과 관련이 없는 레코드(row)를 표시하지 않습니다.
표시되지 않는 레코드는 실제로 삭제되지 않고 일시적으로만 숨겨지는 것이므로 언제든지 복원할 수 있습니다.
Table은 사용자가 작성한 산식(expression)으로 필터링 됩니다. 효과적으로 필터링 하려면 다음 몇가지 기본 산식(expression)을 알아야 합니다.
Why is filtering important?
- 필터링을 사용하면 불필요한 데이터 없이 테이블에서 가장 중요한 데이터를 볼 수 있습니다. 월드컵 통계가 있는 큰 Table을 가지고 있고 그 중 1990년대에 열렸던 그 월드컵들에 대한 통계만 보고 싶다고 가정해 봅시다.
테이블에 어떤 필터링도 적용되지 않는다면, 관련 없는 데이터에 의해 산만해 지거나 혼란스러울 가능성이 커집니다. 필터링을 적용하면 1990년대에 발생한 월드컵에 대한 데이터만 볼 수 있습니다.
Creating a Filter
- 필터를 생성하는 방법에는 몇 가지가 있는데 여기에서는 아래의 2가지 방법을 소개합니다
- 레코드를 선택한 후 R-클릭하는 방법
- 필터 박스를 사용하는 방법
- 데이터 메뉴의 하위 메뉴인 Select 메뉴를 선택하는 방법은 Select 편에서 자세하게 소개하도록 하겠습니다.
R-클릭하는 방법
- 필터링을 하는 가장 간단한 방법은 다음과 같습니다.
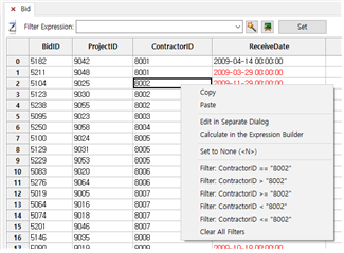
① 특정 칼럼의 특정 셀을 선택하고 오른쪽 클릭을 하여 Filter 조건을 선택하면 됩니다.
Filter Box를 이용하는 방법
- 두번째 방법은 필터 상자를 사용하는 것입니다. 필터 상자를 사용한 필터링은 사용자 지정이 용이하기 때문에 R-클릭 방법보다 더 강력합니다.
하지만 필터 상자를 사용하려면 식을 직접 입력해야 합니다. 따라서 필터 상자는 필터링 산식(Expression)에 대한 이해가 높을수록 강력하게 활용할 수 있습니다.
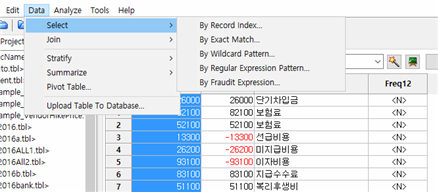
Select 메뉴
- Data 메뉴의 하위 메뉴인 Select 메뉴는 아래와 같이 “By Record Index..”, “By Exact Match...”, “By Wildcard Pattern...”, “By Regular Expression Pattern...”, “By Fraudit Expression...”으로 구분됩니다.
- Record Index
- Exact Match
- Wildcard Pattern
- Regular Expression-1
- Regular Expression-2
- Simple Expressions
- Complex Expressions
Select By Record Index 메뉴

예제파일 중 Bid.tbl을 선택하고 불러옵니다.
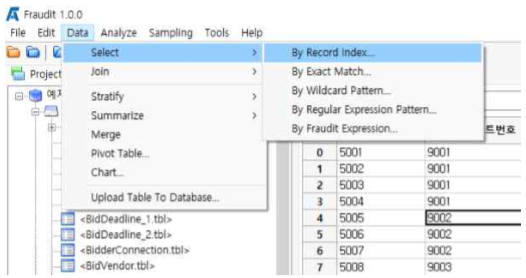
Data >> Select >> By Record Index 메뉴를 선택합니다.
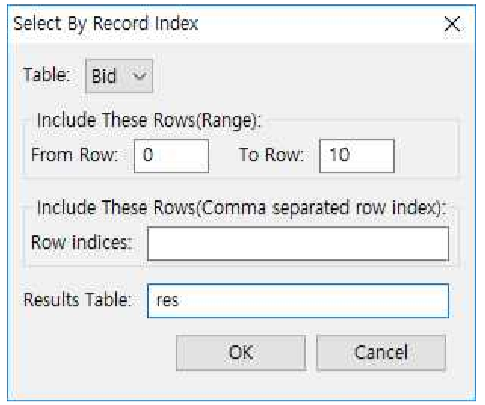
① Table을 드롭다운 리스트에서 Bid로 선택합니다.
② Include These Rows(Range)에서 선택하고 싶은 row 의 인덱스의 범위를 입력합니다. 여기서는 From Row에 0을 입력하고 To Row에 10을 입력해서 0~10 row(총 11개)를 선택하기로 합니다.
③ Results Table 박스에 테이블 명을 res로 기입한 후 OK 버튼을 누릅니다.
② Include These Rows(Range)에서 선택하고 싶은 row 의 인덱스의 범위를 입력합니다. 여기서는 From Row에 0을 입력하고 To Row에 10을 입력해서 0~10 row(총 11개)를 선택하기로 합니다.
③ Results Table 박스에 테이블 명을 res로 기입한 후 OK 버튼을 누릅니다.
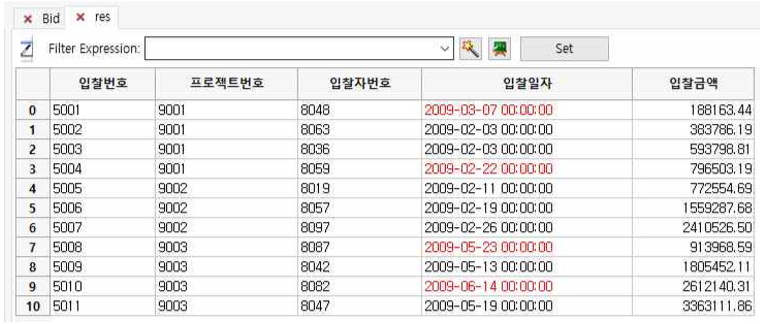
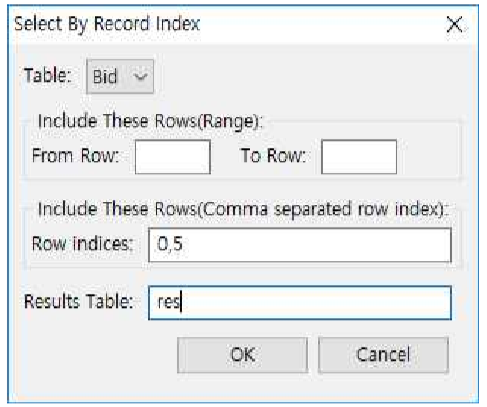
☞ 만약, 선택하고 싶은 row의 인덱스의 범위가 아니라 별도의 레코드를 하나 하나씩 선택하고 싶으시다면
① Include These Rows(Comma separated row index)에서 선택하고 싶은 row의 인덱스를 하나 하나씩 입력 하되 콤마로 구분합니다. 여기서는 Row indices에 0,5 를 입력하여 2개의 레코드만 선택하기로 합니다.
② Results Table 박스에 테이블 명을 res로 기입한 후 OK 버튼을 누릅니다..
① Include These Rows(Comma separated row index)에서 선택하고 싶은 row의 인덱스를 하나 하나씩 입력 하되 콤마로 구분합니다. 여기서는 Row indices에 0,5 를 입력하여 2개의 레코드만 선택하기로 합니다.
② Results Table 박스에 테이블 명을 res로 기입한 후 OK 버튼을 누릅니다..

Select By Exact Match 메뉴
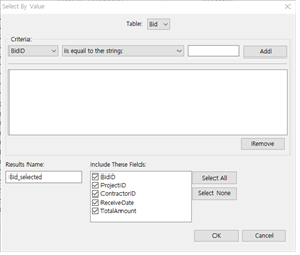
① Data >> Select >> By Exact Match 메뉴를 선택합니다.
② Table을 드롭다운 리스트에서 선택합니다.
③ Criteria에서 필드(칼럼)를 선택하고 조건을 선택한 후 박스에 숫자나 String을 입력하고 Add 버튼을 누르면 상자에 식이 들어가게 됩니다.
④ Results Name을 정하고,
⑤ Include These Fields에서 포함시키고 싶은 필드를 체크한 후 OK 버튼을 누르면 해당 부분만을 필터링한 결과가 별도 Table로 생성됩니다.
② Table을 드롭다운 리스트에서 선택합니다.
③ Criteria에서 필드(칼럼)를 선택하고 조건을 선택한 후 박스에 숫자나 String을 입력하고 Add 버튼을 누르면 상자에 식이 들어가게 됩니다.
④ Results Name을 정하고,
⑤ Include These Fields에서 포함시키고 싶은 필드를 체크한 후 OK 버튼을 누르면 해당 부분만을 필터링한 결과가 별도 Table로 생성됩니다.
Select By Wildcard Pattern 메뉴
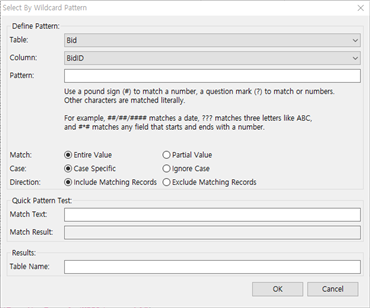
① Data >> Select >> By Wildcard Pattern.. 메뉴를 선택합니다.
② Table, Column을 선택하고 Pattern에 찾고 싶은 text, 숫자 등을 입력합니다.
③ Match에서는 전체가 일치하는지, 일부가 일치하는지를 선택하고,
④ Case는 Case Specific을 선택한다.
⑤ Direction은 해당 조건이 포함되는 것을 필터링하는 경우에는 Include Matching Records를, 해당 조건을 제외하는 경우에는 Exclude Matching Records를 선택합니다.
⑥ Quick Pattern Test에서 Pattern에 넣었던 text, 숫자 등을 다시 입력하면, Match Result에서 결과를 빨리 보여줍니다.
결과가 안 나오면 No match for this pattern라고 보여주고 결과가 나오면 Successful match for this pattern이라고 보여줍니다.
⑦ Results에 테이블 명을 기입하고 OK 버튼을 누르면 해당 테이블이 생성됩니다.
② Table, Column을 선택하고 Pattern에 찾고 싶은 text, 숫자 등을 입력합니다.
③ Match에서는 전체가 일치하는지, 일부가 일치하는지를 선택하고,
④ Case는 Case Specific을 선택한다.
⑤ Direction은 해당 조건이 포함되는 것을 필터링하는 경우에는 Include Matching Records를, 해당 조건을 제외하는 경우에는 Exclude Matching Records를 선택합니다.
⑥ Quick Pattern Test에서 Pattern에 넣었던 text, 숫자 등을 다시 입력하면, Match Result에서 결과를 빨리 보여줍니다.
결과가 안 나오면 No match for this pattern라고 보여주고 결과가 나오면 Successful match for this pattern이라고 보여줍니다.
⑦ Results에 테이블 명을 기입하고 OK 버튼을 누르면 해당 테이블이 생성됩니다.
Select By Regular Expression메뉴 - 1
① Data >> Select >> By Regular Expression.. 메뉴를 선택합니다.
② 파이썬의 정규식(Regular Expression)을 사용한다는 점을 제외하고는 Select By Wildcard Pattern.. 메뉴의 사용방법과 거의 유사합니다.
② 파이썬의 정규식(Regular Expression)을 사용한다는 점을 제외하고는 Select By Wildcard Pattern.. 메뉴의 사용방법과 거의 유사합니다.
Select By Regular Expression메뉴 - 2
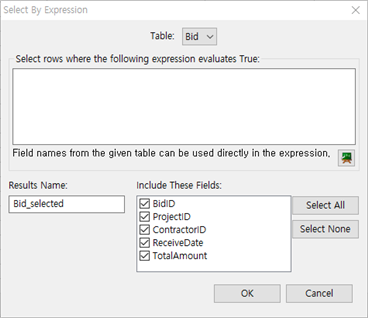
① Data >> Select >> By Fraudit Expression.. 메뉴를 선택합니다.
② Expression 입력창에 직접 입력하거나 아래 Expression 아이콘을 눌러 Expression builder에서 식을 입력할 수 있습니다.
③ Results_Name에서 테이블명을 별도로 정할 수 있습니다.
④ 포함해서 보여줄 필드를 체크박스로 선택할 수 있습니다.
⑤ Results에 테이블 명을 기입하고 OK 버튼을 누르면 해당 테이블이 생성됩니다.
② Expression 입력창에 직접 입력하거나 아래 Expression 아이콘을 눌러 Expression builder에서 식을 입력할 수 있습니다.
③ Results_Name에서 테이블명을 별도로 정할 수 있습니다.
④ 포함해서 보여줄 필드를 체크박스로 선택할 수 있습니다.
⑤ Results에 테이블 명을 기입하고 OK 버튼을 누르면 해당 테이블이 생성됩니다.
Simple Expressions
- 간단한 Expression을 사용하여 column 값을 지정된 값과 비교할 수 있습니다. 이러한 Expression은 정리한 것은 아래와 같습니다.
여기서 유의할 점은 equal to(같다)는 기호가 (=)가 아니라 (==)임을 유의하기 바랍니다(파이썬의 문법이 이와 같다는 점도 기억하기 바랍니다).
| Expression | Literal | Example |
|---|---|---|
| > | Greater Than | WorldCup > 1957 |
| < | Less Than | GoalScored < 40 |
| >= | Greater Than or Equal to | GamesPlayed >= 35 |
| <= | Less Than or Equal to | AvgGameGoals <= 2.8 |
| == | Equal to | Expulsion == 5 |
| != | Not Equal to | GoldenGoals != 0 |
Complex Expressions
- 복수의 column을 서로 비교하거나 ‘and’, ‘or’, ‘and not’ 및 ‘or not’과 같은 피연산자를 사용하여 둘 이상의 간단한 Expression을 결합하여 복잡한 Expression을 만들 수 있습니다.
각 Expression의 예는 아래 표와 같다. 각 피연산자는 반드시 괄호에 있어야 합니다.
필터는 대 소문자를 구분하여야 하며 열 이름도 표시되는 대로 입력해야 합니다. 예를 들어, 컬럼 이름이 “WorldCup”이라면, 필터는 “worldcup”이라는 이름을 인식하지 못하므로 정확히 입력하여야 합니다.
| Expression | Example |
|---|---|
| and | (WorldCup > 1957 and GoalScored < 40) |
| or | (GoalScored < 40 or GoalScored >= 50) |
| and not | (GamesPlayed >= 35 and not GamesPalyed > = 55) |
| or not | (AvgGameGoals <= 2.8 or not AvgGameGoals > 3.1) |
| Multiple column | PenaltyGolas + Expulsions < 9 |
| PenaltyGolas < Expulsions | |
| GoalScored / AvgGameGoals > GamesPalyed |
Join 메뉴
-
Join은 두 테이블을 연결하는 것입니다. 이 기능을 사용하면 두 Table에서 정보를 가져와 지정한 값에 따라 하나의 Table로 결합할 수 있습니다.
이를 통해 Table을 빠르게 비교하고 두 표의 정보를 동시에 사용할 수 있습니다.
Join by Value
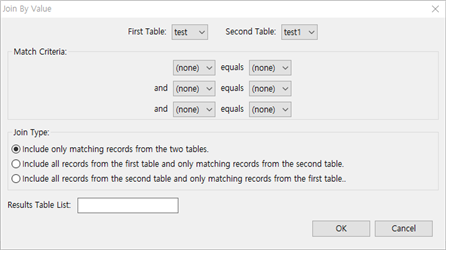
① Data >> Join >> By Value.. 메뉴를 선택합니다.
② Match Criteria에서 첫 번째 Table의 칼럼과 두 번째 Table의 칼럼의 값이 일치하는 지 여부를 3가지 and 조건으로 찾을 수 있습니다.
③ Join Type에서는 3가지 중 하나를 선택할 수 있습니다.
ⓐ 두 Table에서 Match Criteria를 충족하는 record만 포함하는 형태
ⓑ 첫 번째 Table은 모든 record를 포함하고 두 번째 Table에서 Match Criterial를 충족하는 항목만 포함하는 형태 → Vlookup 기능과도 유사한 결과를 가져옵니다.
ⓒ 두 번째 Table은 모든 record를 포함하고 첫 번째 Table에서 Match Criterial를 충족하는 항목만 포함하는 형태
④ Results Table List : 새로운 Table명을 입력한 후 OK 버튼을 누르면 Join Table이 생성됩니다.
② Match Criteria에서 첫 번째 Table의 칼럼과 두 번째 Table의 칼럼의 값이 일치하는 지 여부를 3가지 and 조건으로 찾을 수 있습니다.
③ Join Type에서는 3가지 중 하나를 선택할 수 있습니다.
ⓐ 두 Table에서 Match Criteria를 충족하는 record만 포함하는 형태
ⓑ 첫 번째 Table은 모든 record를 포함하고 두 번째 Table에서 Match Criterial를 충족하는 항목만 포함하는 형태 → Vlookup 기능과도 유사한 결과를 가져옵니다.
ⓒ 두 번째 Table은 모든 record를 포함하고 첫 번째 Table에서 Match Criterial를 충족하는 항목만 포함하는 형태
④ Results Table List : 새로운 Table명을 입력한 후 OK 버튼을 누르면 Join Table이 생성됩니다.
- Join하고 싶은 Table을 결정할 때 다음과 같은 점을 유의하여야 합니다.
- 지정한 두 column에 일치하는 값이 없으면 결과 테이블이 공백이 됩니다. 이것은 실수가 아닙니다. 단지 그 열에 일치하는 값이 없다는 것을 의미할 뿐입니다.
- 둘 이상의 조건으로 Join 할 수 있습니다. 이렇게 하면 결과를 정렬하고 원하는 행을 결정하는 데 걸리는 시간을 절약할 수 있습니다.
- 값에 연결할 Table을 두 Table의 Join을 설명하는 논리적 이름으로 지정해야 합니다. 그렇게 하면 덜 혼란스러워 질 것이고 Table에 참여하려고 할 때 프로그램에서 오류 메시지를 표시하지 않을 것입니다.
- Join by Value의 경우, Table의 두 값이 정확히 일치해야 합니다. Join by Fuzzy Match의 경우 두 값이 반드시 정확하지 않아도 됩니다.
- Join을 사용하면 많은 레코드를 검색할 때 상당한 시간을 절약할 수 있습니다.
예를 들어, 고객 정보가 포함된 Table과 거래에 대한 정보가 있는 다른 Table이 있는 경우, Join을 통해 각 고객과 해당 거래에 대한 특정 정보를 결정할 수 있습니다.
첫 번째 Table의 고객 ID가 두 번째 Table의 고객 ID와 일치하는 Join을 수행하기만 하면 됩니다. 결과 표에는 고객 ID, 정보 및 고객이 참여한 각 거래가 포함됩니다. - 이 특정 Join을 사용하면 고객 ID별로 각 Table을 정렬한 다음 첫 번째 Table에서 원하는 고객 ID를 찾아 두 번째 Table의 고객 ID와 비교하여 고객이 어떤 거래에 참여했는지 확인해야 하는 번거로움을 줄일 수 있습니다.
MS Excel의 사용자라면 vlookup 함수에 익숙할텐데 Join 기능을 잘 활용하면 Excel의 vlookup과 유사한 결과를 쉽게 얻을 수 있습니다.
Join by Fuzzy Match
- Table을 Join 하는 경우에 정확히 일치하지 않을 수 있기 때문에 Fraudit은 Fuzzy matching 기능을 제공합니다.
이렇게 하면 Table의 column을 비교하여 정확히 일치하지는 않지만 비슷한 위치에 Join을 만들 수 있습니다. - 어느 칼럼의 string이 ‘match’라면, 다른 Table의 칼럼에 있는 이름 중 비슷하게 찾을 수 있는 예는 다음과 같습니다.
- match
- matched
- matcher
- matching
- matchbox
- Fraudit의 Fuzzy matching 알고리즘은 강력한 matching 방법입니다.
하지만, Fuzzy matching 알고리즘은 텍스트 내의 조건을 적용할 때 굉장히 많은 조건을 적용하여야 하기 때문에 알고리즘 내에서 시나리오는 기하급수적으로 증가할 수 있습니다.
이 때문에 현재 속도를 높이는 방법을 연구 중이지만 데이터베이스나 Fraudit의 정규 Join 명령 사용과 같은 정상적인 인덱스를 사용하는 것은 불가능합니다.
대신에, Fuzzy matching 알고리즘은 첫 번째 Table의 개별 값과 두 번째 Table의 개별 값을 매치합니다. 예를 들어, 각각 10개의 레코드가 있는 두 개의 Table이 있다고 가정해 봅시다. 첫 번째 Table의 개별 값을 두 번째 테이블의 개별 값과 비교하려면 100개(10×10)의 레코드를 비교해야 합니다.
만약 각각 1000개의 레코드가 있는 두개의 Table을 가지고 있다고 가정해 보면 100만개(1000×1000)의 비교 자료를 가지고 있게 됩니다.
두개의 테이블에 각각 10,000개의 레코드가 있다고 가정해 보면 이는 1억개(10000×10000)를 비교하는 것과 같습니다. - 다음은 Fuzzy matching으로 테이블을 조인하는 방법을 설명하는 사례입니다.
- 상기와 같이 Join된 테이블이 별도로 생성됩니다. D열과 D_1열을 보면『매도가능증권』과 『매도 가능주식』이 정확하게 일치하지 않아도 Fuzzy로 Join된 것을 알 수 있습니다
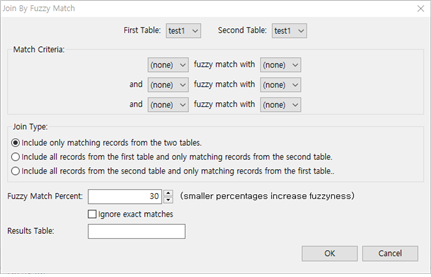
① Data >> Join >> By Fuzzy Match.. 메뉴를 선택합니다.
② Match Criteria에서 첫 번째 Table의 칼럼과 두 번째 Table의 칼럼의 값이 Fuzzy match 하는지 여부를 3가지 and 조건으로 찾을 수 있습니다.
③ Join Type에서는 3가지 중 하나를 선택할 수 있습니다.
ⓐ 두 Table에서 Match Criteria를 충족하는 record만 포함하는 형태
ⓑ 첫 번째 Table은 모든 record를 포함하고 두 번째 Table에서 Match Criterial를 충족하는 항목만 포함하는 형태
ⓒ 두 번째 Table은 모든 record를 포함하고 첫 번째 Table에서 Match Criterial를 충족하는 항목만 포함하는 형태
④ Fuzzy Match Percent에서 퍼센트를 결정합니다. 이 퍼센트가 높을수록 Fuzzy가 감소되고 낮을수록 Fuzzy가 증가합니다(Fuzzy가 증가한다는 의미는 그만큼 정확하지 않은 값들이 매칭될 수 있다는 의미입니다).
⑤ Results Table : 새로운 Table명을 입력한 후 OK 버튼을 누르면 Join Table이 생성됩니다.
② Match Criteria에서 첫 번째 Table의 칼럼과 두 번째 Table의 칼럼의 값이 Fuzzy match 하는지 여부를 3가지 and 조건으로 찾을 수 있습니다.
③ Join Type에서는 3가지 중 하나를 선택할 수 있습니다.
ⓐ 두 Table에서 Match Criteria를 충족하는 record만 포함하는 형태
ⓑ 첫 번째 Table은 모든 record를 포함하고 두 번째 Table에서 Match Criterial를 충족하는 항목만 포함하는 형태
ⓒ 두 번째 Table은 모든 record를 포함하고 첫 번째 Table에서 Match Criterial를 충족하는 항목만 포함하는 형태
④ Fuzzy Match Percent에서 퍼센트를 결정합니다. 이 퍼센트가 높을수록 Fuzzy가 감소되고 낮을수록 Fuzzy가 증가합니다(Fuzzy가 증가한다는 의미는 그만큼 정확하지 않은 값들이 매칭될 수 있다는 의미입니다).
⑤ Results Table : 새로운 Table명을 입력한 후 OK 버튼을 누르면 Join Table이 생성됩니다.

Join by Expression
- Join by Expression은 사용자가 Expression Box에 다양한 조건을 직접 넣어 Join을 할 수 있는 기능을 제공합니다.
- 다만, Expression Box에서는 다음과 같은 규칙에 따라 산식을 넣어야 합니다
- 첫 번째 Table의 레코드는 record1이라고 하여야 하며, 두 번째 Table의 레코드는 record2라고 하여야 합니다.
- record1 또는 record2뒤에 “.칼럼명”을 붙입니다.
예를 들어, 첫 번째 Table의 ID라는 칼럼과 두 번째 Table의 ID라는 칼럼이 일치하는 경우 Join을 하게 하려면 Expression Box내에 다음과 같이 산식을 넣어야 합니다. - and 또는 or 조건을 걸 수도 있습니다.
record1.ID == record2.ID
Stratify(계층화)
- 일반적으로 Stratify 기능은 특정 칼럼의 값이 여러 개로 구성될 때 이를 그룹핑하여 보여주는 기능을 말합니다.
- MS Excel에서는 Stratify 기능이 기본적으로 제공되지 않습니다.
따라서 filter를 여러번 한 후 그것을 복사해서 별도의 테이블을 만드는 작업을 하거나 이것을 매크로 또는 VBA로 코딩을 해야 하는 번거로움이 있습니다. - Fraudit의 Stratify는 타 소프트웨어의 Stratify기능 보다 훨씬 유연하고 강력한 기능을 제공합니다.
타 소프트웨어의 경우 숫자 칼럼(integer나 decimal) 칼럼에 대해서만 Stratify(계층화)하여 각 계층별 레코드 수와 분포를 구하는데 반하여 Fraudit의 Stratify는 숫자 칼럼 뿐만 아니라 string 및 DateTime 칼럼에 대해서도 stratify기능을 적용할 수 있습니다.
이하에서는 예제를 가지고 Stratify기능에 대해서 설명하기로 합니다.
- Stratify By Value
- Stratify By Date Column
- Stratify Into A Specified Number of Groups
- Combine Table List
- 동영상 설명
Stratify by Value
단일 칼럼에 대하여 stratify 하기
- 먼저 "Bid.tbl" 파일을 연 후, Data >> Stratify >> By Value 를 누르고 아래와 같이 설정합니다.
- "Bid.tbl" 파일을 연 후, Data >> Stratify >> By Value를 누르고 아래와 같이 설정합니다.
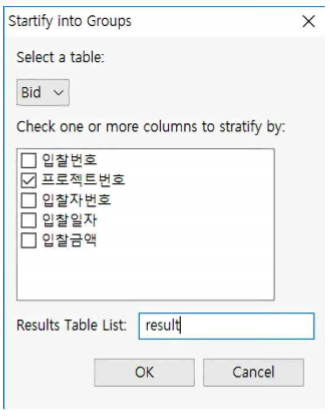
① Select a table : Bid로 선택
② Check one or more columns to stratify by ➠『프로 젝트번호』 체크
③ Results Table List : result라고 입력
② Check one or more columns to stratify by ➠『프로 젝트번호』 체크
③ Results Table List : result라고 입력
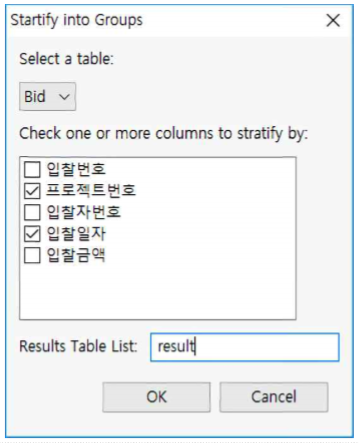
①『프로젝트번호』칼럼으로 stratify 한 결과 64개(오른쪽 상단 스크롤바의 숫자)의 계층화가 이루어집니다.
0부터 시작되는 이유는 Python에서 리스트 구조의 카운트를 0부터 시작하도록 되어 있기 때문입니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
복수 칼럼에 대해서 stratify 하기
① Select a table : Bid로 선택
② Check one or more columns to stratify by ➠ 프로젝트번호와 입찰일자 체크
③ Results Table List : result라고 입력
② Check one or more columns to stratify by ➠ 프로젝트번호와 입찰일자 체크
③ Results Table List : result라고 입력

①『프로젝트번호』칼럼과『입찰일자』칼럼으로 stratify 한 결과 262개(오른쪽 상단 스크롤바의 숫자)의 계층화가 이루어집니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
Stratify By Date Column
- "Bid.tbl" 파일을 연 후, Data >> Stratify >> By Date Column을 누르고 아래와 같이 설정합니다.
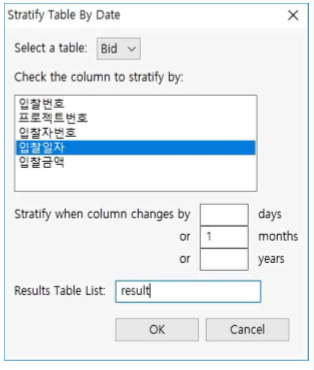
① Select a table : Bid로 선택
② Check the column to stratify by ➠ 데이터 형식이 DateTime인 ReceiveDate 칼럼을 선택합니다.
③ Stratify when column changes by
㉮□days에 숫자를 기입하면 해당 일수만큼 구분하여 stratify 해줍니다.
㉯□month에 숫자를 기입하면 해당 월 만큼 Stratify 해준다. 예를 들어 1을 기입하면 1월 단위로 계층화하며, 2를 기입하면 2월 단위로 계층화합니다.
㉰□years에 숫자를 기입하면 해당 년 만큼 Stratify 해준다. 예를 들어, 1을 기입하면 1년 단위로 계층화하며, 2를 기입하면 2년 단위로 계층화합니다.
☞ 여기서는 months에 1을 기입 하고 Results Table List : result라고 입력합니다.
② Check the column to stratify by ➠ 데이터 형식이 DateTime인 ReceiveDate 칼럼을 선택합니다.
③ Stratify when column changes by
㉮□days에 숫자를 기입하면 해당 일수만큼 구분하여 stratify 해줍니다.
㉯□month에 숫자를 기입하면 해당 월 만큼 Stratify 해준다. 예를 들어 1을 기입하면 1월 단위로 계층화하며, 2를 기입하면 2월 단위로 계층화합니다.
㉰□years에 숫자를 기입하면 해당 년 만큼 Stratify 해준다. 예를 들어, 1을 기입하면 1년 단위로 계층화하며, 2를 기입하면 2년 단위로 계층화합니다.
☞ 여기서는 months에 1을 기입 하고 Results Table List : result라고 입력합니다.
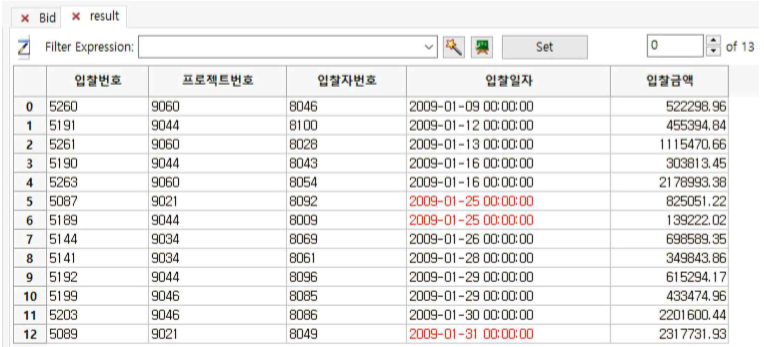
① ReceiveDate 칼럼으로 stratify 한 결과 13개(오른쪽 상단 스크롤바의 숫자)의 계층화가 이루어집니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
Stratify Into A Specified Number of Groups
- “Bid.tbl” 파일을 연후, Data >> Statify >> Specified Number of Groups를 누르고 아래와 같이 설정합니다.
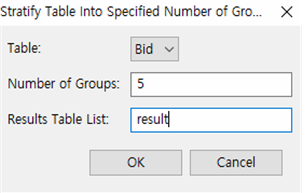
① Select a table : Bid로 선택
② Number of Groups ➠ 전체 테이블을 5개로 계층화합니다. 계층화는 현재 정렬상태에서 이루어집니다. 기준으로 5개로 합니다.
③ Results Table List : result라고 입력합니다.
② Number of Groups ➠ 전체 테이블을 5개로 계층화합니다. 계층화는 현재 정렬상태에서 이루어집니다. 기준으로 5개로 합니다.
③ Results Table List : result라고 입력합니다.
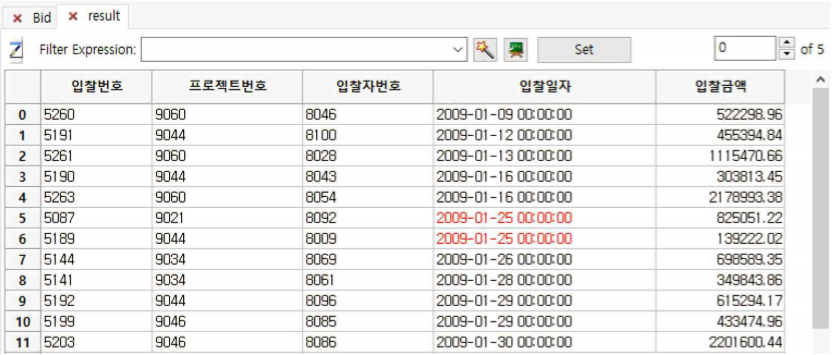
① stratify 한 결과 5개(오른쪽 상단 스크롤바의 숫자)의 계층화가 이루어집니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
Combine Table List
- Combine Table List는 Fraudit의 강력한 기능 중 하나입니다. 이는 Stratify한 sub table 별로 각기 산식을 넣은 후 합칠 수 있는 기능으로 original table에서 직접 처리하기 어려운 경우에 사용하는 기능입니다.
이는 뒤에 설명할 Summarize 기능과 연계한 후 간단한 script를 짜주면 더욱 강력한 분석을 할 수 있습니다.
동영상 설명
Summarize(요약화)
- 요약(Summarize)은 합계, 평균, 표준 편차, 개수 등의 요약 기능을 사용하여 계층화된 테이블을 다시 조합할 수 있는 기능이다.
요약(Summarize)은 해당 기간 동안 구매자당 총 구매액을 계산하거나, 가장 많이 거래되는 공급처를 찾는 경우에 유용하다.
요약(Summarize)은 구조화된 쿼리 언어의 GROUPBy와 유사하다.
Summarize By Value
단일 컬럼에 대하여 Summarize 하기
- 먼저 "Bid.tbl"파일을 연 후, Data >> Summarize >> By Value를 누르고 아래와 같이 설정합니다.
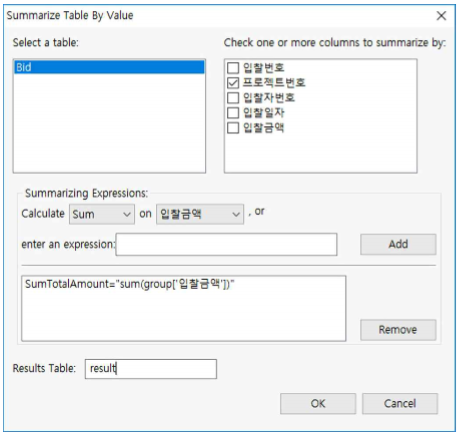
① Select a table : Bid로 선택
Check one or more columns to summarize by ➠ 프 로젝트번호 체크
③ Summarizing Expressions:
⒜ Calculate ➠ Sum 선택
⒝ on ➠ TotalAmount 선택
④ Add 버튼을 클릭 합니다.
⑤ input Text 창에서 칼럼명을 기입합니다. 여기서는 SumTotalAmount라고 기입합니다.
⑥ Results Table : result라고 기입한 후 OK 버튼을 누릅니다.
Check one or more columns to summarize by ➠ 프 로젝트번호 체크
③ Summarizing Expressions:
⒜ Calculate ➠ Sum 선택
⒝ on ➠ TotalAmount 선택
④ Add 버튼을 클릭 합니다.
⑤ input Text 창에서 칼럼명을 기입합니다. 여기서는 SumTotalAmount라고 기입합니다.
⑥ Results Table : result라고 기입한 후 OK 버튼을 누릅니다.
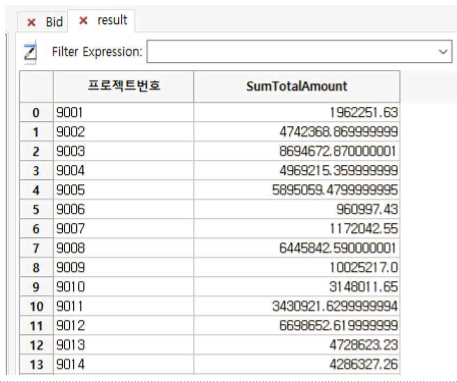
프로젝트번호를 64개로 stratify 한 후 각각의 계층에 대해서 TotalAmount의 Sum이 표시된 것을 확인할 수 있습니다.
☞ Bid 테이블과 연계하여 설명하면 다음과 같습니다.
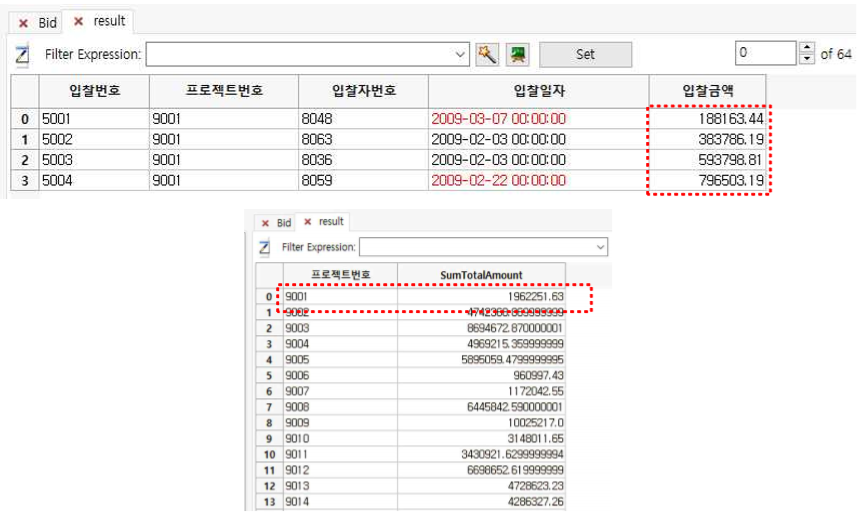
복수 컬럼에 대하여 Summarize 하기
- 먼저 "purchases.tbl" 파일을 연 후, Data >> Summarize >> By Value 를 누르고 아래와 같이 설정합니다.
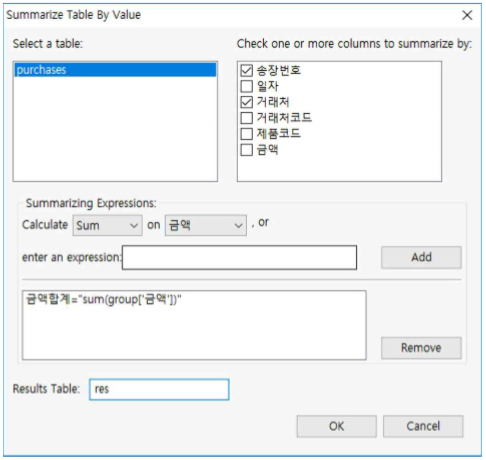
① Select a table : purchases로 선택
② Check one or more columns to summarize by ➠ 『송장번호』와『거래처』를 체크
③ Summarizing Expressions:
⒜ Calculate ➠ Sum 선택
⒝ on ➠ TotalAmount 선택
④ [ Add ] 버튼을 누른다.
⑤ input Text 창에서 칼럼명을 기입합니다. 여기서는 『금액합계』라고 기입합니다
⑥ Results Table : res라고 기입한 후 OK 버튼을 누릅니다.
② Check one or more columns to summarize by ➠ 『송장번호』와『거래처』를 체크
③ Summarizing Expressions:
⒜ Calculate ➠ Sum 선택
⒝ on ➠ TotalAmount 선택
④ [ Add ] 버튼을 누른다.
⑤ input Text 창에서 칼럼명을 기입합니다. 여기서는 『금액합계』라고 기입합니다
⑥ Results Table : res라고 기입한 후 OK 버튼을 누릅니다.
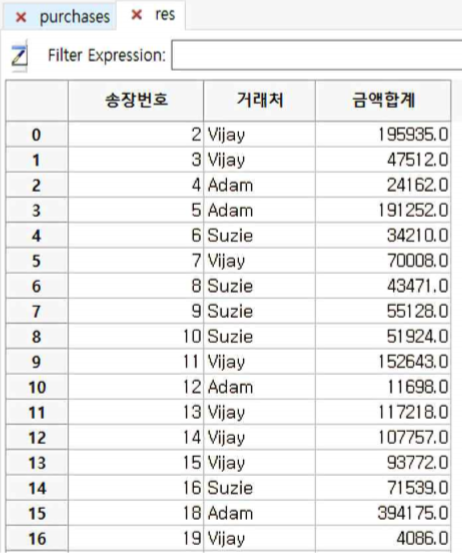
①『송장번호』와『거래처』에 대해서 stratify 한 후 각각의 계층에 대해서 금액합계가 표시된 것을 확인 할 수 있습니다.
Summarize By Date Column
- 먼저 "Bid.tbl" 파일을 연 후, Data >> Summarize >> By Date Column 를 누르고 아래와 같이 설정합니다.
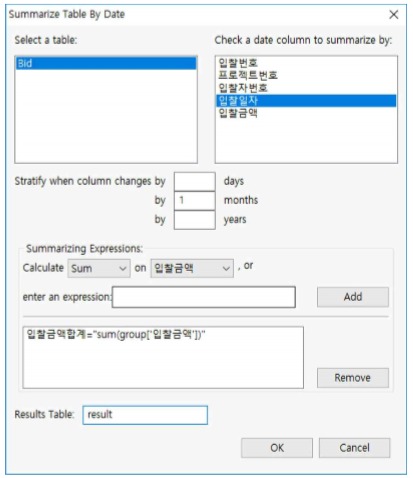
① Select a table : Bid로 선택
② Check one or more columns to summarize by ➠ 입 찰일자를 체크(데이터 타입이 DateTime이 아닌 칼럼 을 선택하는 경우 에러가 발생합니다).
③ Stratify when column changes by : by 1 months로 1을 기입합니다.
④ [ Add ] 버튼을 누른다.
⑤ input Text 창에서 칼럼명을 기입한다. 여기서는 SumTotalAmount라고 기입합니다.
⑥ Results Table : result라고 기입한 후 [ OK ] 버튼을 누른다.
② Check one or more columns to summarize by ➠ 입 찰일자를 체크(데이터 타입이 DateTime이 아닌 칼럼 을 선택하는 경우 에러가 발생합니다).
③ Stratify when column changes by : by 1 months로 1을 기입합니다.
④ [ Add ] 버튼을 누른다.
⑤ input Text 창에서 칼럼명을 기입한다. 여기서는 SumTotalAmount라고 기입합니다.
⑥ Results Table : result라고 기입한 후 [ OK ] 버튼을 누른다.
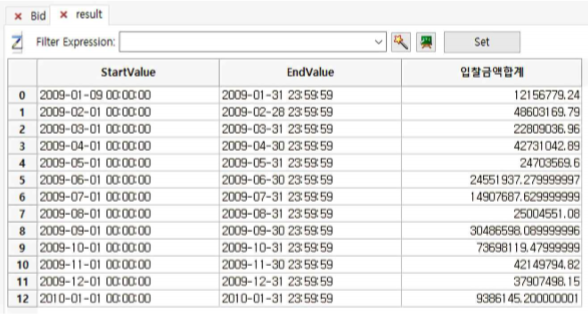
① 1개월별로 stratify된 계층별 TotalAmount의 Sum이 표시됩니다.
Summarize Existing Table List
- Summarize Existing Table List는 이미 Stratify된 sub table이 생성된 상태에서 Summarize 기능을 적용하는 것으로, 굳이 original table에 돌아가서 Summarize 기능을 적용하지 않아도 되는 편리한 기능입니다.
사용 방법은 1과 2와 거의 유사하므로 앞의 내용을 참조하기 바랍니다.
Pivot Table
- MS Excel에서 Pivot Table 기능을 사용해본 경험이 있으면 Fraudit의 Pivot Table기능을 쉽게 이해할 수 있습니다.
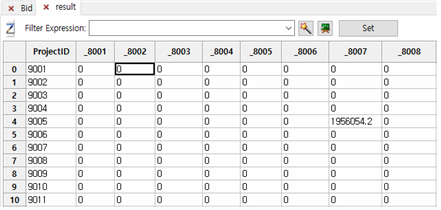
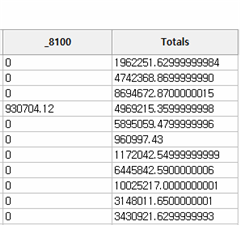
사실 Fraudit의 Pivot Table기능은 MS Excel에서 Pivot Table 기능과 거의 유사합니다. - 먼저 “Bid.tbl” 파일을 연후, Data >> Pivot Table을 누르고 아래와 같이 합니다.
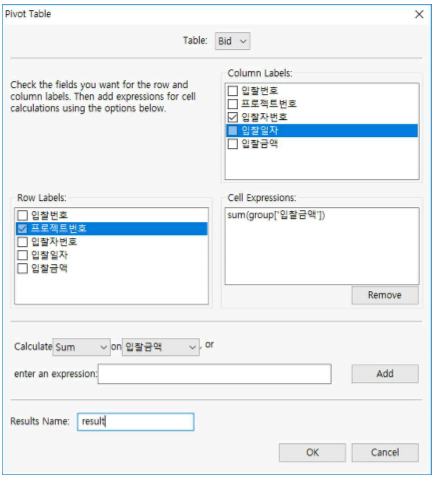
① Table : Bid로 선택
② Row Labels : 프로젝트번호 체크
③ Column Labels : 입찰자번호 체크
④ Cell Expressions
⒜ Calculate Sum 을 선택하고,
⒝ on TotalAmount 를 선택한 후
Add 버튼을 누르면 Cell Expression에 입력합니다.
⑤ Results Table : result라고 기입한 후 OK 버튼을 누릅니다.
② Row Labels : 프로젝트번호 체크
③ Column Labels : 입찰자번호 체크
④ Cell Expressions
⒜ Calculate Sum 을 선택하고,
⒝ on TotalAmount 를 선택한 후
Add 버튼을 누르면 Cell Expression에 입력합니다.
⑤ Results Table : result라고 기입한 후 OK 버튼을 누릅니다.
Analyze 메뉴
Descriptives
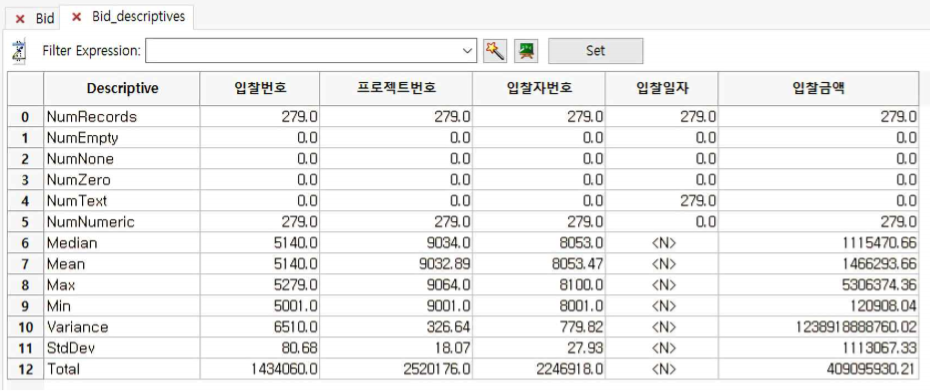
- Descritptives기능은 테이블의 칼럼별로 개수, 최대, 최소값, 평균, 중간값, 최빈치, 표준편차, 분산, 합계, 빈 레코드, None 레코드, text 개수를 한번에 보여주어,
테이블에 대한 전체적인 조망을 할 수 있게 해줍니다. - 먼저 “Bid.tbl” 파일을 연후, Analyze >> Descritptives 을 누르면 다음과 같은 결과 테이블이 생성됩니다.
Benford Analysis
- Benford 법칙이란,
- 금액의 첫째 단위인 1~9까지의 숫자와 둘째 단위인 0~9까지의 숫자가 전체 모집단에서 나올 확률(예: 앞의 두 숫자가 23이라면 첫째 단위에서 2가 나올 확률과 둘째 단위에서 3일 나올 확률)과
- 금액의 앞에서 두단위가 전체 모집단에서 나올 확률(예: 앞의 두 숫자가 23이라면 10~99사에서 23이 나올 확률이
- 따라서 어떤 금액의 첫째 단위와 둘째 단위 또는 앞의 두단위가 상기 표의 확률분포에서 많이 벗어난 경우 의도적인 조작이 포함되었을 가능성이 높다는 것입니다.
- Benford 법칙에 따라 테스트할 때 어떤 기준을 가지고 테스트 할 것인지를 결정하는 것이 중요하다. 계정과목 특성을 무시하고 단순히 모든 금액 하나 하나를 Benford 법칙에 따라 테스트하는 것은 효과적이지 않습니다.
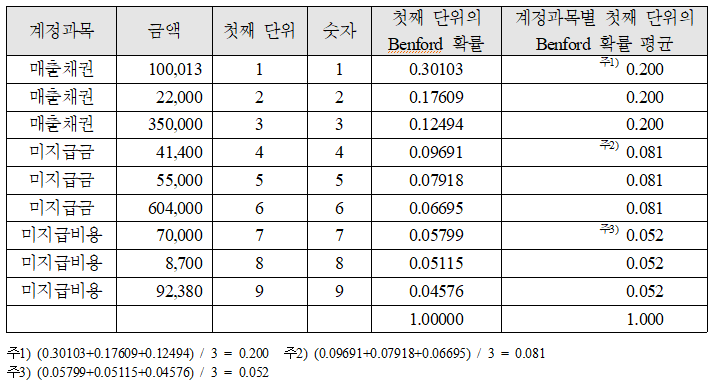
다음의 사례를 들어보겠습니다.
만약 어떤 회사의 거래가 아래와 같이 9개만 있고 이것이 모두 Benford 법칙에 따른다면 언뜻 보기에 문제가 없어 보일 수 있습니다. 하지만 계정과목별 첫째 단위의 Benford 법칙 평균(average)을 구해보면 상황은 달라집니다. - 미지급비용은 다른 계정과목과 달리 첫째 단위가 높은 숫자에 몰려있다보니 Benford 법칙에 따른 발생확률의 평균이 매우 낮아지게 됩니다.
이와 같이 매출채권, 미지급금, 미지급비용의 첫째 단위가 특정 구간에 집중되어 있다면(각각 1~3, 4~6, 7~9) 어떤 계정과목의 부정가능성이 높을까요?
Benford 법칙은 확률론적이고 경험적인 방법이므로 절대적으로 어떤 계정과목이 부정가능성이 높다고 말하기는 어렵습니다.
그렇지만 상대적으로 계정과목별 첫째 단위의 Benford 확률의 평균이 낮으면 낮을수록 특정 계정과목의 분포가 높은 숫자에 몰려있을 가능성이 높기 때문에 이는 상대적으로 낮은 숫자에 몰려있을 가능성보다 드문 경우에 해당합니다. 따라서 계정과목별 첫째 단위의 Benford 확률의 평균이 낮으면 낮을수록 부정의 개입 가능성은 상대적으로 크다고 볼 수 있습니다. - 여기서는 사례 PurchaseTransaction.tbl을 가지고 설명하도록 하겠다. 먼저 Purchase Transaction.tbl을 열고 다음의 절차대로 수행합니다.
- 이제 AccountNum별로 통합하여 테스트를 할 것이므로 AccountNum별 Amount 첫째 단위의 Benford 법칙 예상 확률을 가지고 테스트 할 것입니다.
경우에 따라서는, 거래처 코드 등으로 통합하여 테스트를 할 수 있습니다.
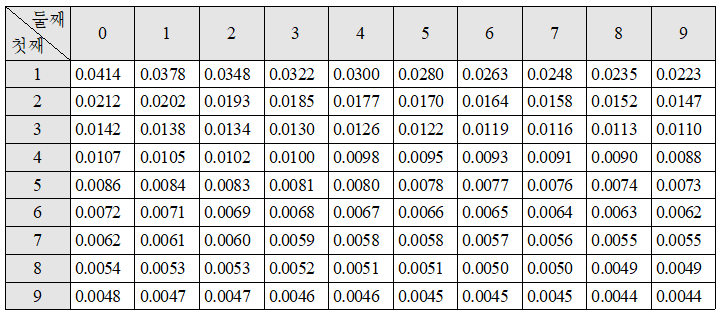
【표 】 Benford 법칙에 따른 첫째 단위(1~9)와 둘째 단위(0~9)가 나올 확률
| 숫자 | Benford_둘째 단위 | Benford_둘째 단위 |
|---|---|---|
| 0 | 0.11968 | |
| 1 | 0.30103 | 0.11389 |
| 2 | 0.17609 | 0.10882 |
| 3 | 0.12494 | 0.10433 |
| 4 | 0.09691 | 0.10031 |
| 5 | 0.07918 | 0.09668 |
| 6 | 0.06695 | 0.09337 |
| 7 | 0.05799 | 0.09035 |
| 8 | 0.05115 | 0.08757 |
| 9 | 0.04576 | 0.08500 |
| 1.00000 | 1.00000 |
【표 】 Benford 법칙에 따른 앞에서 두 단위가 나올 확률
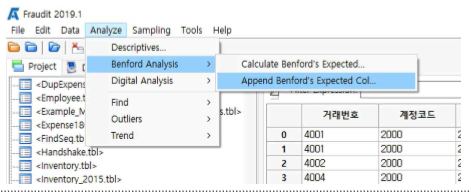
① Analyze >> Benford Analysis >> Append Benford’s Expected...를 누릅니다.
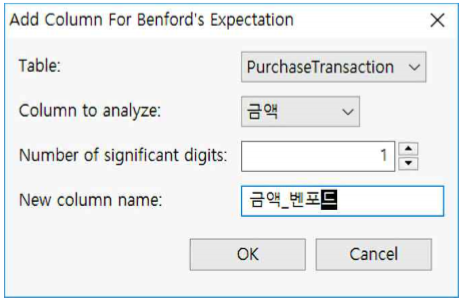
② Table과 Column을 왼쪽과 같이 세팅하고,
③ Number of significant digits은 1을 선택합니다.
④ New column name은『금액_벤포드』로 입력합니다.
③ Number of significant digits은 1을 선택합니다.
④ New column name은『금액_벤포드』로 입력합니다.
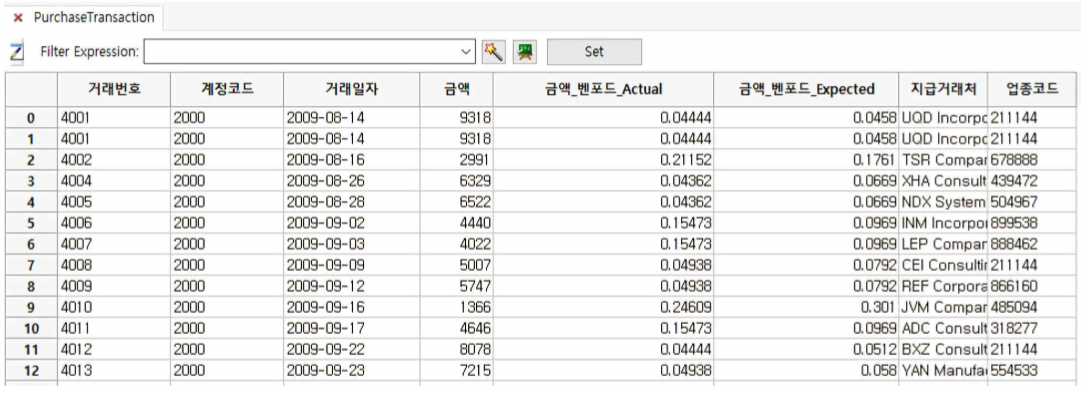
⑤ 금액_벤포드_Actual 확률(실제 확률)과 금액_벤포드_Expected 확률(Benford 법칙에 따른 기대확 률) 칼럼이 오른쪽에 추가 됩니다.
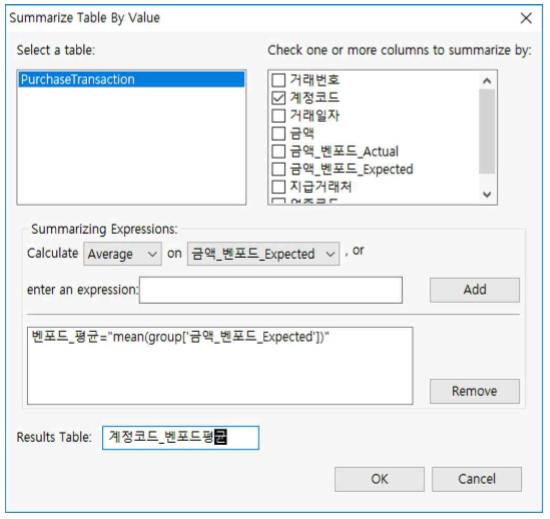
① Data >> Summarize >> By Value 를 누릅니다.
② Check one or more columns to summarize by에서 『계정코드』를 체크합니다.
③Summarizing Expressions에서 Average와 금액_벤포드_Expected를 선택하고
④ Add 버튼을 누른 후『벤포드_평균』이라고 입력합니다.
⑤ Results Table에서 Table명을『계정코드_벤포드평 균』이라고 입력한 후 OK버튼을 누릅니다.
② Check one or more columns to summarize by에서 『계정코드』를 체크합니다.
③Summarizing Expressions에서 Average와 금액_벤포드_Expected를 선택하고
④ Add 버튼을 누른 후『벤포드_평균』이라고 입력합니다.
⑤ Results Table에서 Table명을『계정코드_벤포드평 균』이라고 입력한 후 OK버튼을 누릅니다.
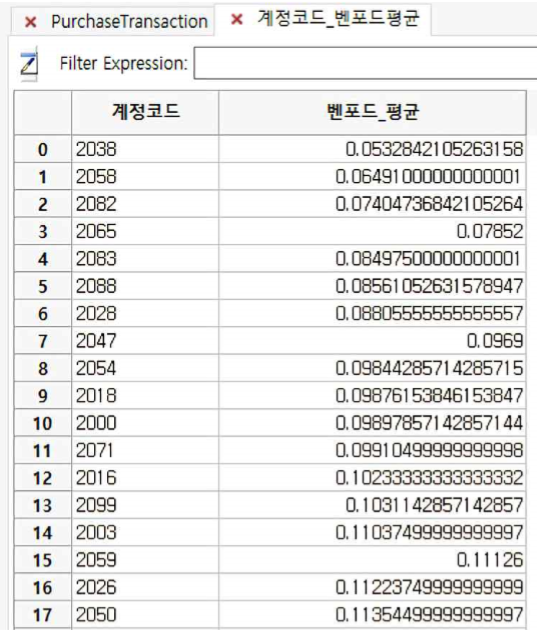
⑥ AvgB 칼럼을 오름차순으로 정렬합니다.
☞ AccountNum 2038, 2058, 2082의 Benford 확률 평균이 가장 낮은 편에 속합니다.
Benford 확률 평균이 낮으면 낮을수록 가상의 숫자일 가능성이 높아진다는 것은 이미 설명하였습니다.
따라서 상기 AccountNum 2038, 2058, 2082에 대해서는 추가적인 조사가 필요할 것입니다.
☞ AccountNum 2038, 2058, 2082의 Benford 확률 평균이 가장 낮은 편에 속합니다.
Benford 확률 평균이 낮으면 낮을수록 가상의 숫자일 가능성이 높아진다는 것은 이미 설명하였습니다.
따라서 상기 AccountNum 2038, 2058, 2082에 대해서는 추가적인 조사가 필요할 것입니다.
Digital Analysis
- Digital Analysis 기능은 분석이 필요한 칼럼에 대하여 아래와 같은 분석 칼럼을 옆에 추가해줍니다.
Add Percentage Column
- Add Percentage Column : 특정 칼럼의 전체 합산에서 각 레코드의 차지하는 비율을 백분율로 보여줍니다.
- “test.tbl” 파일을 연후, Analyze >> Digital Analysis >> Add Percentage Column 를 누른 후 다음과 같이 설정합니다.
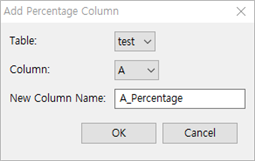
① Table : test 선택
② Column : A 선택
③ New Column Name : 특별히 기입하지 않으면 테이블명_Percentage로 자동 생성됩니다. 여기서는 A_Percentage로 합니다.
④ [ OK ] 버튼을 누릅니다.
② Column : A 선택
③ New Column Name : 특별히 기입하지 않으면 테이블명_Percentage로 자동 생성됩니다. 여기서는 A_Percentage로 합니다.
④ [ OK ] 버튼을 누릅니다.
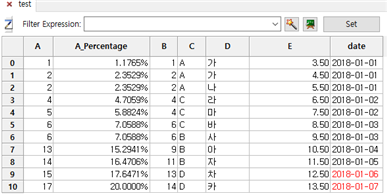
⑤ A 칼럼 옆에 A_Percentage 칼럼이 추가되면서 A 칼럼 전체 합산에서 A 칼럼 각 레코드 값이 차지하는 비율을 % 포맷으로 보여줍니다.
Add Cumsum Column
- Add Cumsum Column은 특정 칼럼의 레코드 순서대로 누적합산액을 계산하여 줍니다.
- “test.tbl” 파일을 연후, Analyze >> Digital Analysis >> Add Cumsum Column 를 누른 후 다음과 같이 설정합니다.
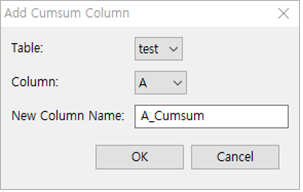
① Table : test 선택
② Column : A 선택
③ New Column Name : 특별히 기입하지 않으면 테이블명_Cumsum로 자동 생성됩니다. 여기서는 A_Cumsum로 합니다.
④ [ OK ] 버튼을 누릅니다.
② Column : A 선택
③ New Column Name : 특별히 기입하지 않으면 테이블명_Cumsum로 자동 생성됩니다. 여기서는 A_Cumsum로 합니다.
④ [ OK ] 버튼을 누릅니다.
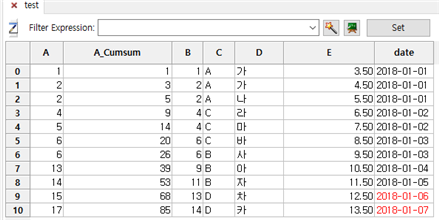
⑤ A 칼럼 옆에 A_Cumsum 칼럼이 추가되면서 A 칼럼의 레코드 순서대로 누적합산액을 보여줍니다.
Add Cumsubtract Column
- Add Cumsubtract Column은 특정 칼럼의 레코드 순서대로 누적차감액을 계산하여 줍니다.
- “test.tbl” 파일을 연후, Analyze >> Digital Analysis >> Add Cumsubtract Column 를 누른 후 다음과 같이 설정합니다.
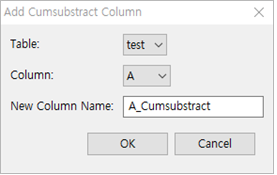
① Table : test 선택
② Column : A 선택
③ New Column Name : 특별히 기입하지 않으면 테이블명_Cumsubstract로 자동 생성됩니다. 여기서는 A_Cumsubtract로 합니다.
④ [ OK ] 버튼을 누릅니다.
② Column : A 선택
③ New Column Name : 특별히 기입하지 않으면 테이블명_Cumsubstract로 자동 생성됩니다. 여기서는 A_Cumsubtract로 합니다.
④ [ OK ] 버튼을 누릅니다.
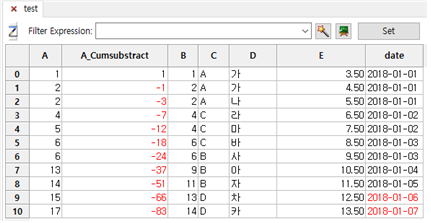
⑤ A 칼럼 옆에 A_Cumsubstract 칼럼이 추가되면서 A 칼럼의 레코드 순서대로 누적차감액을 보여줍니다.
Add Shift Column
- Add Shift Column은 특정 칼럼의 레코드의 순서를 하나씩 내리거나 올린 칼럼을 보여줍니다.
- “test.tbl” 파일을 연후, Analyze >> Digital Analysis >> Add Shift Column 를 누른 후 다음과 같이 설정합니다.
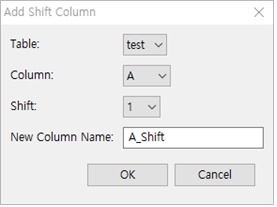
① Table : test 선택
② Column : A 선택
③ Shift : 1 또는 –1을 선택합니다. 1을 선택하면 순서를 하나씩 내린 칼럼을 보여주고, -1을 선택하면 순서를 하나씩 올린 칼럼을 보여줍니다.
④ New Column Name : 특별히 기입하지 않으면
테이블명_Shift로 자동 생성됩니다.
여기서는 A_Shift 로 합니다.
⑤ OK 버튼을 누릅니다.
② Column : A 선택
③ Shift : 1 또는 –1을 선택합니다. 1을 선택하면 순서를 하나씩 내린 칼럼을 보여주고, -1을 선택하면 순서를 하나씩 올린 칼럼을 보여줍니다.
④ New Column Name : 특별히 기입하지 않으면
테이블명_Shift로 자동 생성됩니다.
여기서는 A_Shift 로 합니다.
⑤ OK 버튼을 누릅니다.
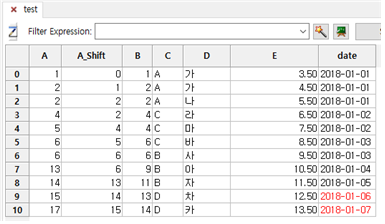
⑥ A 칼럼 옆에 A_Shift 칼럼이 추가되면서 A 칼럼의 레코드의 순서를 하나씩 내린 칼럼을 보여줍니다.
Add Vlookup Column
- Add Shift Column은 Excel의 Vlookup 기능과 유사한 기능을 제공합니다.
- “test.tbl” 과 “test1.tbl” 파일을 연후, Analyze >> Digital Analysis >> Add Vlookup Column을 누른 후 다음과 같이 설정합니다.
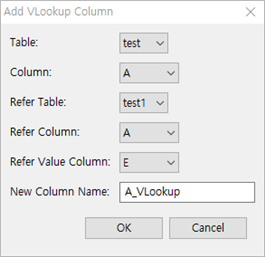
① Table : test 선택
② Column : A 선택
③ Refer Table : test1 선택
④ Refer Column : A 선택
☞ Refer Column은 중복값이 없는 Column 이어야 합니다.
⑤ New Column Name : 특별히 기입하지 않으면
테이블명_VLookup 으로 자동 생성됩니다.
여기서는 A_VLookup 으로 합니다.
⑤ OK 버튼을 누릅니다..
② Column : A 선택
③ Refer Table : test1 선택
④ Refer Column : A 선택
☞ Refer Column은 중복값이 없는 Column 이어야 합니다.
⑤ New Column Name : 특별히 기입하지 않으면
테이블명_VLookup 으로 자동 생성됩니다.
여기서는 A_VLookup 으로 합니다.
⑤ OK 버튼을 누릅니다..
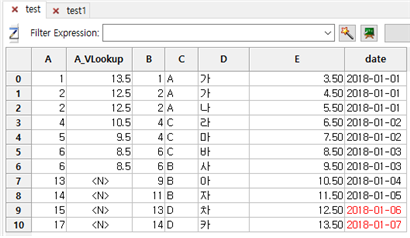
⑥ A 칼럼 옆에 A_VLookup 칼럼이 추가되면서 test1 테이블의 E값을 VLookup하여 갖고 오고 해당 값이 없으면 N 이 표시됩니다.
Find
Duplicates
- Duplicates 기능은 특정 칼럼에서 중복된 값이 있는 경우 해당 row를 보여주는 기능입니다.
- 먼저 “PurchaseTransaction.tbl” 파일을 연후, Analyze >> Find >> Duplicates 를 누른 후 다음과 같이 설정합니다.
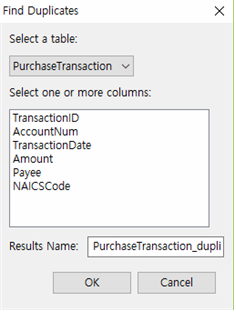
① Select a Table : PurchaseTransaction을 선택
② Select one or more columns : TransactionID 선택
③ Results Name : 특별히 기입하지 않으면 “원 테이블명_duplcates”로 자동 생성됩니다. 여기서는 PurchaseTransaction_duplicates로 합니다.
④ OK 버튼을 누릅니다.
② Select one or more columns : TransactionID 선택
③ Results Name : 특별히 기입하지 않으면 “원 테이블명_duplcates”로 자동 생성됩니다. 여기서는 PurchaseTransaction_duplicates로 합니다.
④ OK 버튼을 누릅니다.

⑤ 0과 1 row(index)에서 TransactionID가 4001이 중복으로 나온 것을 확인할 수 있습니다.
Gaps
- Gap 기능은 선택한 칼럼의 연속성, 즉, 누락여부를 테스트하는 것입니다. 이는 어음수표 번호의 연속성, 재고실사 Tag 번호의 연속성, 발주서 번호의 연속성, 전표번호의 연속성 등을 검증할 때 사용할 수 있습니다.
Integer에 대해서만 분석이 가능하며, 한 번에 하나의 칼럼만이 선택가능합니다. Gap기능은 테스트를 하기 전에 파일이 먼저 sorting(Ascending)되어 있어야 합니다. - 먼저 “PurchaseTransaction.tbl” 파일을 연후, Analyze >> Find >> Gaps 를 누른 후 다음과 같이 설정합니다.
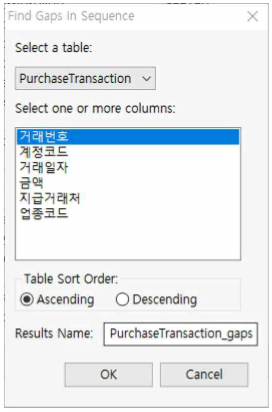
①『거래번호』의 데이터 타입을 integer로 설정한다.
②『거래번호』가 Ascending으로 정렬되어 있는지 확인합니다.
③ Select a Table : PurchaseTransaction을 선택
④ Select one or more columns : 『거래번호』 선택
⑤ Table Sort Order : Ascending으로 선택합니다.
⑥ Results Name : 특별히 기입하지 않으면 “원 테이블명_gaps”로 자동 생성됩니다. 여기서는 PurchaseTransaction_gaps로 합니다.
⑦ OK 버튼을 누릅니다.
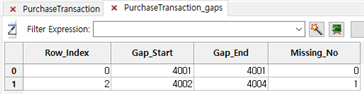
① 0 row(index)와 1 row(index)는 duplicate인 동시에 gap이 됩니다(4001과 4002사이에 중복값 4001 있기 때문에 일종의 gap으로 본다는 의미입니다).
② 2 row(index)와 3 row(index)는 4002와 4004이므로 gap이 된며, Missing Number는 1(4003)이 됩니다.
② 2 row(index)와 3 row(index)는 4002와 4004이므로 gap이 된며, Missing Number는 1(4003)이 됩니다.
Matching by Value
- Matching by Value는 Value값이 일치하는 record를 찾아주는 기능이다. 이 기능은 블랙리스트에 올라간 거래처가 최종 계약을 하였는지 등을 분석할 때 편리한 기능입니다.
- 먼저 “Bid.tbl”과 “Blacklist.tbl”파일을 열고, Analyze >> Find >> Matching by Value 를 누른 후 다음과 같이 설정합니다.
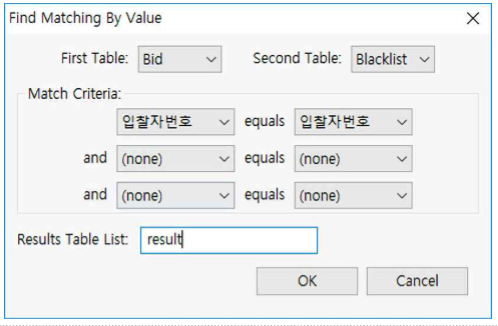
① First Table : Bid를 선택합니다.
② Second Table : Blacklist를 선택합니다.
③ Match Criteria : First Table의『입찰자번호』와
Second Table의 『입찰자번호』를 선택합니다.
④ Results Table List : result로 입력합니다.
⑤ OK 버튼을 누릅니다.
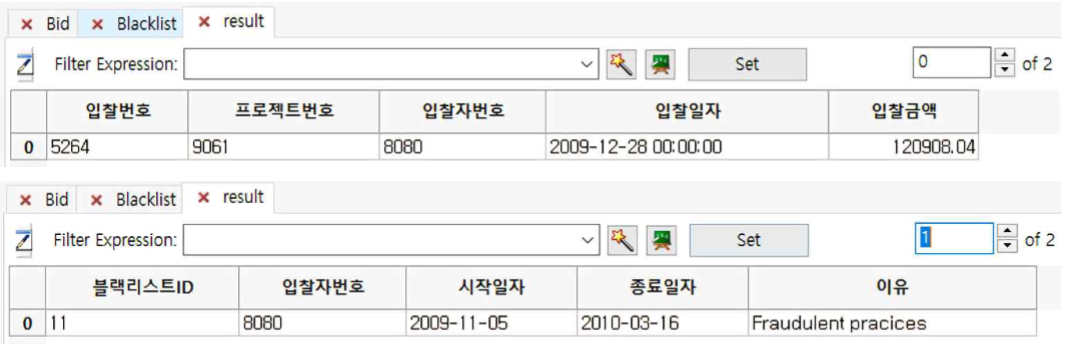
① 첫 번째 sub table은 『입찰자번호』 8080이 계약이 체결된 것을 보여주고 두 번째 sub table은 그 『입찰자번호』 8080이 Blacklist라는 것을 보여줍니다.
즉, ProjectID 9061은 블랙리스트와 계약이 체결된 것을 알 수 있습니다.
즉, ProjectID 9061은 블랙리스트와 계약이 체결된 것을 알 수 있습니다.
Matching by Expression
- Matching by Expression은 Expression을 활용하여 Matching by Value보다 다양한 Matching Criteria를 설정할 수 있는 기능입니다.
- 먼저 “Bid.tbl”과 “Blacklist.tbl”파일을 열고, Analyze >> Find >> Matching by Expression 를 누른 후 다음과 같이 설정합니다.
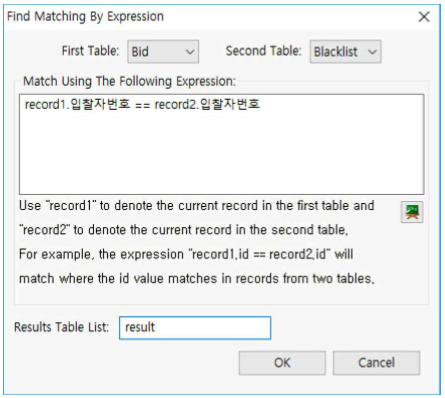
① First Table : Bid를 선택합니다.
② Second Table : Blacklist를 선택합니다.
③ Match Using The Following Expression :
record1.입찰자번호 == record2.입찰자번호을 입력합니다
(이는 첫 번째 table의 입찰자번호 칼럼의 레코드와 두 번째 table의 입찰자번호 칼럼의 레코드가 일치하는 것을 찾으라는 의미입니다).
④ Results Table List : result로 입력합니다.
⑤ OK 버튼을 누릅니다.
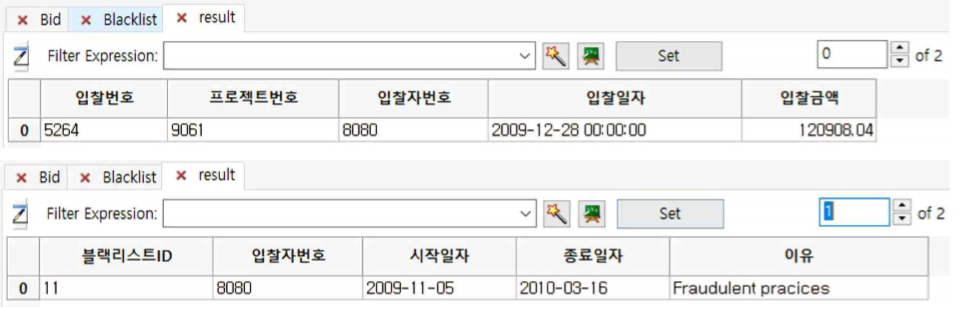
① 첫 번째 sub table은 입찰자번호 8080이 계약이 체결된 것을 보여주고 두 번째 sub table은 그 입찰자번호 8080이 Blacklist라는 것을 보여줍니다.
즉, ProjectID 9061은 블랙리스트와 계약이 체결된 것을 알 수 있습니다.
즉, ProjectID 9061은 블랙리스트와 계약이 체결된 것을 알 수 있습니다.
Nonmatching by Value
- Nonmatching by Value는 Matching by Value의 여집합을 찾아주는 기능입니다.
- 먼저 “Bid.tbl”과 “Blacklist.tbl”파일을 열고, Analyze >> Find >> Nonmatching by Value 를 누른 후 다음과 같이 설정합니다.
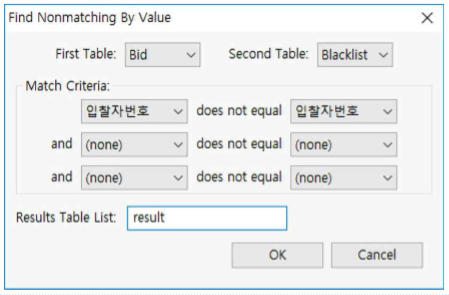
① First Table : Bid를 선택합니다.
② Second Table : Blacklist를 선택합니다.
③ Match Criteria : First Table의『입찰자번호』와
Second Table의『입찰자번호』를 선택합니다.
④ Results Table List : result로 입력합니다.
⑤ OK 버튼을 누릅니다.
② Second Table : Blacklist를 선택합니다.
③ Match Criteria : First Table의『입찰자번호』와
Second Table의『입찰자번호』를 선택합니다.
④ Results Table List : result로 입력합니다.
⑤ OK 버튼을 누릅니다.
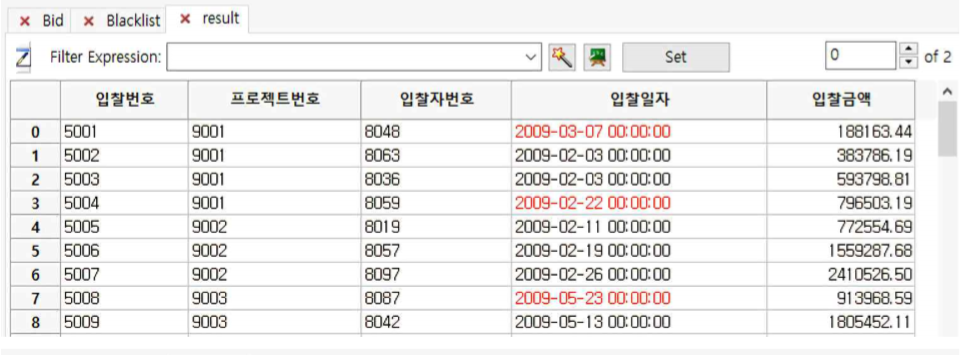
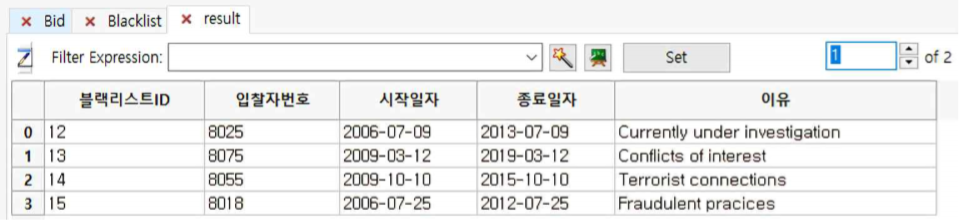
① 첫 번째 sub table은 blacklist가 아닌 계약자와 체결된 현황을 보여주고 두 번째 sub table은 그 ContractorID 8080을 제외한 나머지 Blacklist를 보여줍니다.
즉, 첫 번째 sub table이 블랙리스트와 계약이 체결된 것이 없다는 것을 알 수 있습니다.
즉, 첫 번째 sub table이 블랙리스트와 계약이 체결된 것이 없다는 것을 알 수 있습니다.
Nonmatching by Expression
- Nonmatching by Value는 Matching by Expression의 여집합을 찾아주는 기능입니다.
- 먼저 “Bid.tbl”과 “Blacklist.tbl”파일을 열고, Analyze >> Find >> Nonmatching by Expression 를 누른 후 다음과 같이 설정합니다.
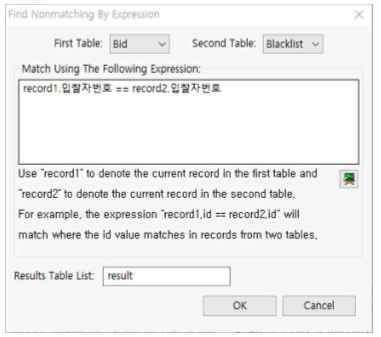
① First Table : Bid를 선택합니다.
② Second Table : Blacklist를 선택합니다.
③ Match Using The Following Expression :
record1.입찰자번호 == record2.입찰자번호를 입력합니다.
(원래 expression의 의미는 첫 번째 table의 입찰자번호 칼럼의 레코드와 두 번째 table의 입찰자번호 칼럼의 레코드가 일치하는 것을 찾으라는 의미이지만 Nonmatching 메뉴이므로 자동적으로 Nonmatchin을 찾아주는 것입니다).
④ Results Table List : result로 입력합니다.
⑤ OK 버튼을 누릅니다.
② Second Table : Blacklist를 선택합니다.
③ Match Using The Following Expression :
record1.입찰자번호 == record2.입찰자번호를 입력합니다.
(원래 expression의 의미는 첫 번째 table의 입찰자번호 칼럼의 레코드와 두 번째 table의 입찰자번호 칼럼의 레코드가 일치하는 것을 찾으라는 의미이지만 Nonmatching 메뉴이므로 자동적으로 Nonmatchin을 찾아주는 것입니다).
④ Results Table List : result로 입력합니다.
⑤ OK 버튼을 누릅니다.
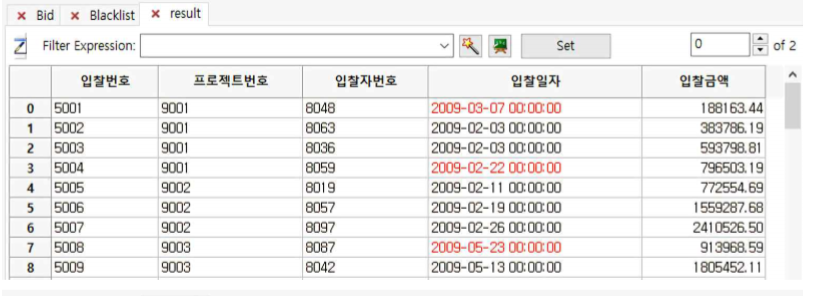
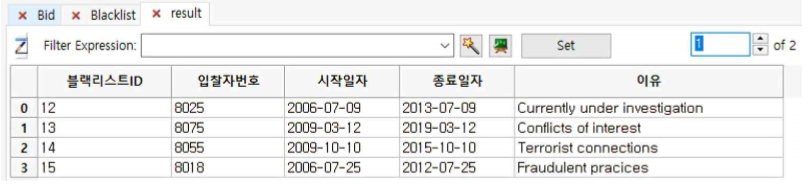
① 첫 번째 sub table은 blacklist가 아닌 계약자와 체결된 현황을 보여주고 두 번째 sub table은 그 ContractorID 8080을 제외한 나머지 Blacklist를 보여줍니다.
즉, 첫 번째 sub table이 블랙리스트와 계약이 체결된 것이 없다는 것을 알 수 있습니다.
즉, 첫 번째 sub table이 블랙리스트와 계약이 체결된 것이 없다는 것을 알 수 있습니다.
Outliers
Add ZScore Column
- ZScore는 통계학적으로 정규분포를 만들고 개개의 경우가 표준편차상에 어떤 위치를 차지하는지를 보여주는 차원없는 수치를 말합니다.
- ZScore의 절대값이 크면 클수록 발생가능성이 낮다는 것을 의미한다. 예를 들어, ZScore가 1.96이면 5%의 발생가능성이 있는 것이며 ZScore가 2.57이면 1%의 발생가능성이 있다는 것입니다.
따라서 어떤 그룹핑 내에서 수치의 ZScore가 매우 크다면 이는 이상치(Outlier)일 가능성이 크다는 것을 의미한다. ZScore에 대한 자세한 설명은 통계교과서 등을 참조하기 바랍니다. - “Bid.tbl” 파일을 열고, Data >> Stratify >> By Value를 누른 후 다음과 같이 설정합니다.
- 이제 Analyze >> Outliers >> Add ZScore Column 을 누른 후 다음과 같이 설정합니다.
- 이제 Data >> Stratify >> Combine Table List를 누르고 다음과 같이 설정합니다.
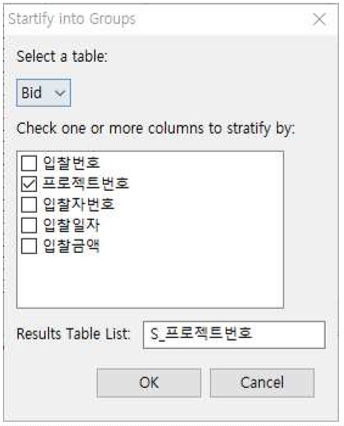
① Select a table : Bid를 선택합니다.
② Check one or more columns to stratify by : ProjectID를 체크합니다.
③ Results Table List : S_ProjectID라고 입력합니다.
④ OK 버튼을 누릅니다.
② Check one or more columns to stratify by : ProjectID를 체크합니다.
③ Results Table List : S_ProjectID라고 입력합니다.
④ OK 버튼을 누릅니다.
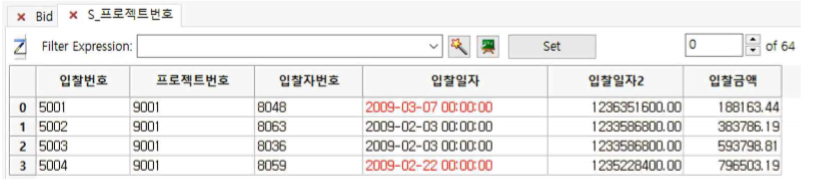
① ProjectID 칼럼으로 stratify 한 결과 64개(오른쪽 상단 스크롤바의 숫자)의 계층화가 이루어집니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
② 오른쪽 상단 스크롤바를 위 아래로 이동하면 stratify된 sub table이 계속해서 바뀌는 것을 확인할 수 있습니다.
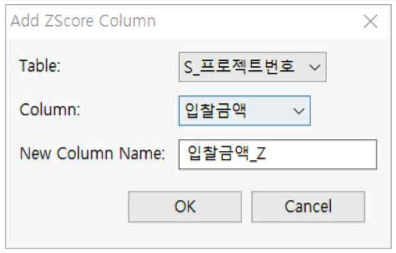
① First Table : S_프로젝트번호를 선택합니다.
② Column : TotalAmount를 선택합니다.
③ New Column Name : 입찰금액_Z라고 입력합니다.
④ OK 버튼을 누릅니다.
② Column : TotalAmount를 선택합니다.
③ New Column Name : 입찰금액_Z라고 입력합니다.
④ OK 버튼을 누릅니다.
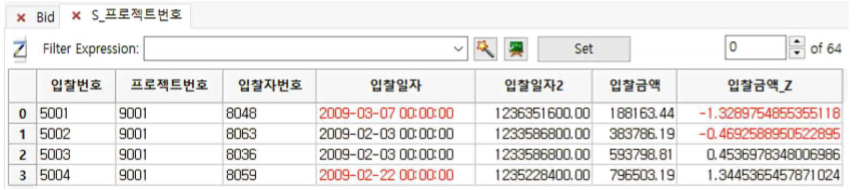
① 프로젝트번호 칼럼으로 stratify 한 sub table의 마지막 칼럼에 입찰금액_Z 칼럼이 삽입되고 ZScore가 나타남을 알 수 있습니다.
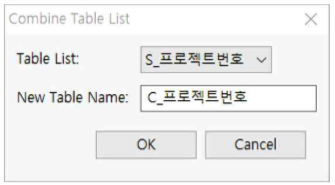
① Table List : S_프로젝트번호를 선택합니다.
② New Table Name : C_프로젝트번호를 입력합니다.
③ OK 버튼을 누릅니다.
② New Table Name : C_프로젝트번호를 입력합니다.
③ OK 버튼을 누릅니다.
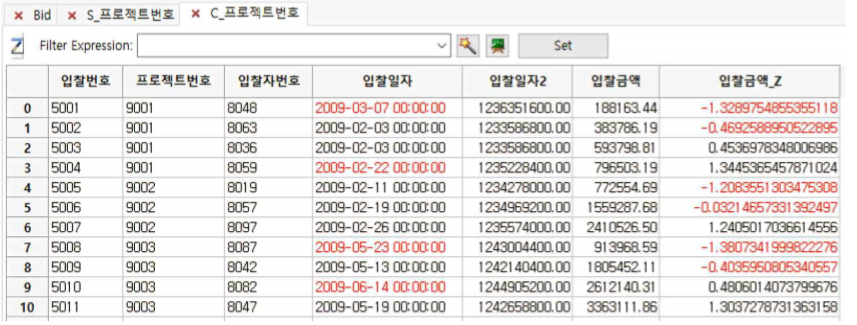
① 입찰금액_Z가 칼럼으로 추가된 단일 테이블으로 합쳐집니다(Combine Table).
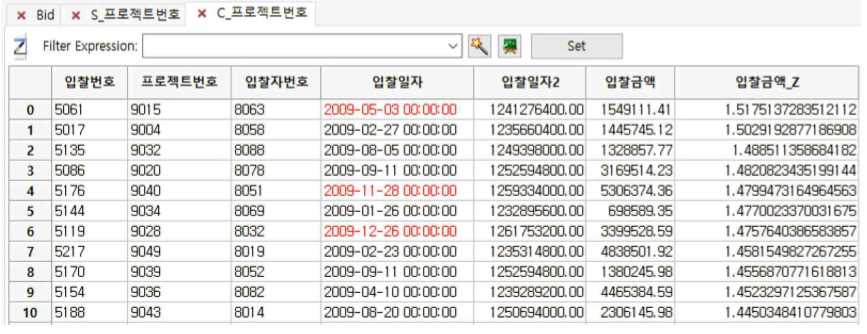
① 입찰금액_Z 칼럼에 대해서 R-Click하여 Sort descending 합니다.
② ZScore가 가장 높은 것이 1.5 정도이므로 추가 분석이 필요한만큼 높지는 않은 편임을 알 수 있습니다.
② ZScore가 가장 높은 것이 1.5 정도이므로 추가 분석이 필요한만큼 높지는 않은 편임을 알 수 있습니다.
Select NonOutliers
- Slsect NonOutliers는 사용자가 설정한 Outlier 임계치 안에 포함되는 NonOutlier만 선택하여 보여주는 기능이다.
- “Bid.tbl” 파일을 열고 Analyze >> Outliers >> Select NonOutliers를 누른 후 다음과 같이 설정합니다.
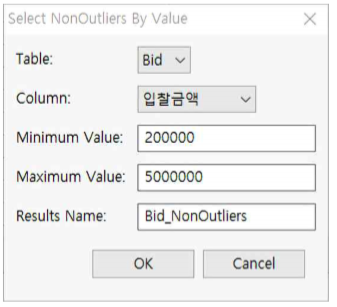
① Table : Bid를 선택합니다.
② Column : 입찰금액을 선택합니다(데이터 타입이 interger 또는 Decimal Number 인 칼럼을 선택하여야 한다).
③ Minimum Value : 200000을 기입합니다.
④ Maximum Value : 5000000을 기입합니다.
⑤ Results Name : Bid_NonOutliers라고 기입합니다.
⑥ OK 버튼을 누릅니다.
② Column : 입찰금액을 선택합니다(데이터 타입이 interger 또는 Decimal Number 인 칼럼을 선택하여야 한다).
③ Minimum Value : 200000을 기입합니다.
④ Maximum Value : 5000000을 기입합니다.
⑤ Results Name : Bid_NonOutliers라고 기입합니다.
⑥ OK 버튼을 누릅니다.
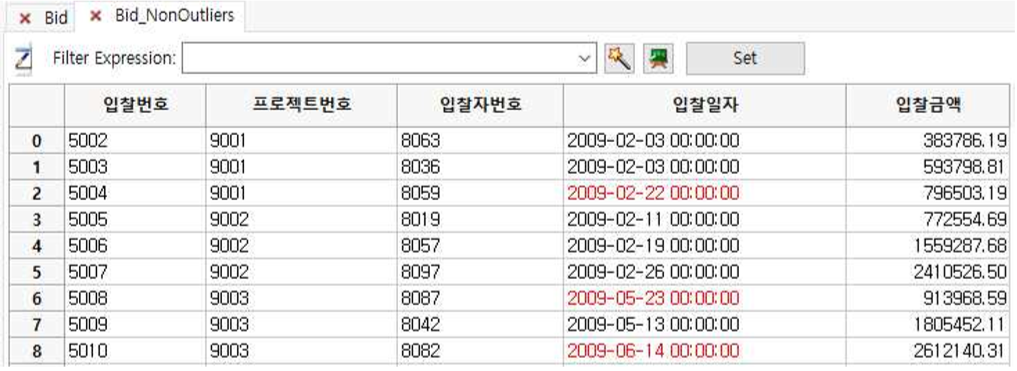
① 입찰금액 칼럼에서 값이 200000이상에서 5000000사이의 record(NonOutliers)만 나타납니다.
Select NonOutliers by ZScore
- Select NonOutlierse by ZScore는 사용자가 설정한 ZScorer 임계치 안에 포함되는 NonOutlier만 선택하여 보여주는 기능입니다.
- “Bid.tbl” 파일을 열고 Analyze >> Outliers >> Select NonOutliers by ZScore를 누른 후 다음과 같이 설정합니다.
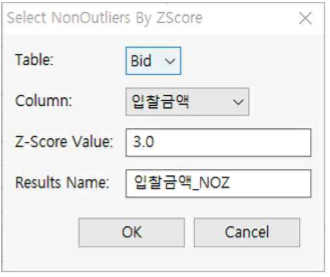
① Table : Bid를 선택합니다.
② Column : 입찰금액을 선택합니다(데이터 타입이 interger 또는 Decimal Number 인 칼럼을 선택하여야 한다).
③ Z-Score Value : 3.0을 기입합니다.
④ Results Name : 입찰금액_NOZ라고 기입합니다.
⑤ OK 버튼을 누릅니다.
② Column : 입찰금액을 선택합니다(데이터 타입이 interger 또는 Decimal Number 인 칼럼을 선택하여야 한다).
③ Z-Score Value : 3.0을 기입합니다.
④ Results Name : 입찰금액_NOZ라고 기입합니다.
⑤ OK 버튼을 누릅니다.
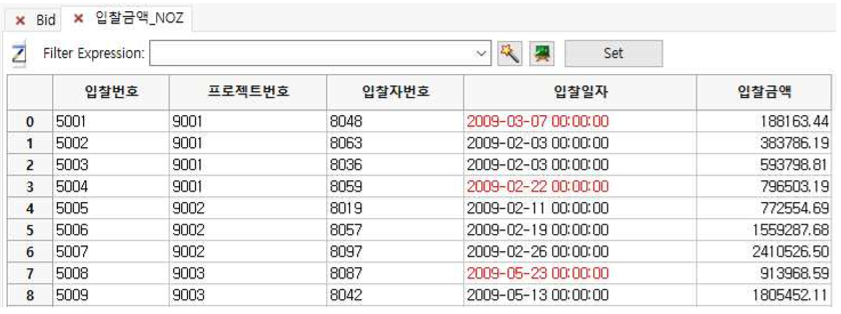
① 입찰금액 칼럼에서 ZScore 값이 –3.0 이상에서 3.0사이의 record(NonOutliers)만 나타납니다.
Select Outliers
- Select Outlierse는 사용자가 설정한 Outlier 임계치를 초과하는 Outlier만 선택하여 보여주는 기능입니다.
- “Bid.tbl” 파일을 열고 Analyze >> Outliers >> Select Outliers를 누른 후 다음과 같이 설정합니다.
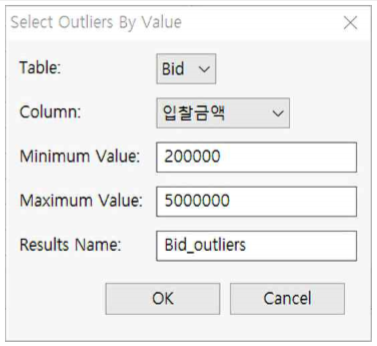
① Table : Bid를 선택합니다.
② Column : 입찰금액을 선택합니다(데이터 타입이 interger 또는 Decimal Number 인 칼럼을 선택하여야 한다).
③ Minimum Value : 200000을 기입합니다.
④ Maximum Value : 5000000을 기입합니다.
⑤ Results Name : Bid_Outliers라고 기입합니다.
⑥ OK 버튼을 누릅니다.
② Column : 입찰금액을 선택합니다(데이터 타입이 interger 또는 Decimal Number 인 칼럼을 선택하여야 한다).
③ Minimum Value : 200000을 기입합니다.
④ Maximum Value : 5000000을 기입합니다.
⑤ Results Name : Bid_Outliers라고 기입합니다.
⑥ OK 버튼을 누릅니다.
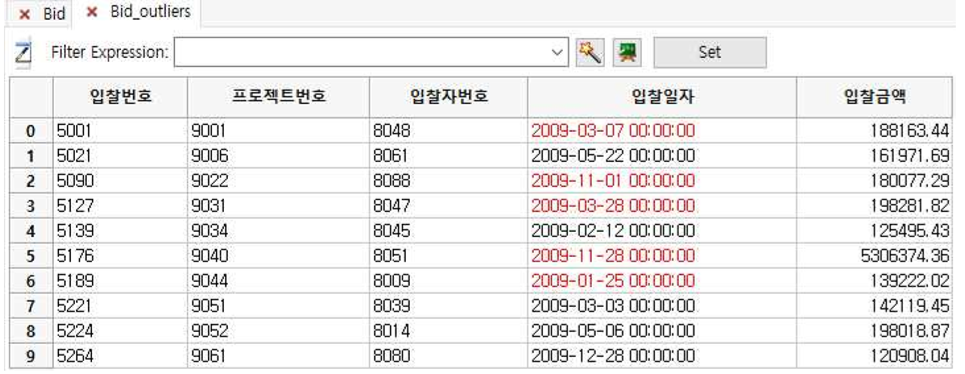
① 입찰금액 칼럼에서 값이 200000 미만 및 5000000 초과하는 record(Outliers)만 나타납니다.
Select Outliers by ZScore
- Select Outlierse by ZScore는 사용자가 설정한 ZScorer 임계치를 벗어나는 Outlier만 선택하여 보여주는 기능입니다.
- “Bid.tbl” 파일을 열고 Analyze >> Outliers >> Select Outliers by ZScore를 누른 후 다음과 같이 설정합니다.
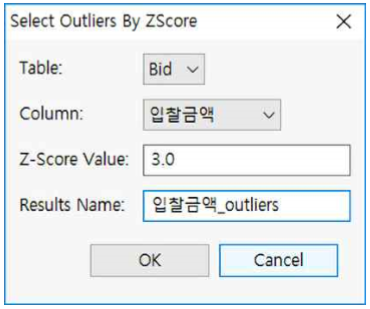
① Table : Bid를 선택합니다.
② Column : 입찰금액을 선택합니다(데이터 타입이 interger 또는 Decimal Number 인 칼럼을 선택하여야 한다).
③ Z-Score Value : 3.0을 기입합니다.
④ Results Name : 입찰금액_outliers라고 기입합니다.
⑤ OK 버튼을 누릅니다.
② Column : 입찰금액을 선택합니다(데이터 타입이 interger 또는 Decimal Number 인 칼럼을 선택하여야 한다).
③ Z-Score Value : 3.0을 기입합니다.
④ Results Name : 입찰금액_outliers라고 기입합니다.
⑤ OK 버튼을 누릅니다.
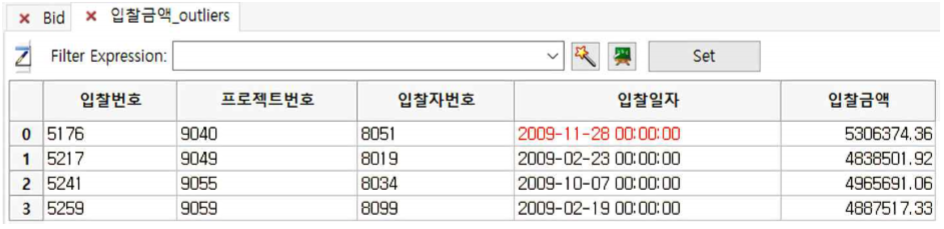
① 입찰금액 칼럼에서 ZScore 값이 –3.0 미만 및 3.0 초과하는 record(Outliers)만 나타납니다.
Trend
Add Cusum Column
- Cusum(누적합)이란 테이블의 각 record 값의 차이를 누적한 것을 말합니다.
Cusum은 어떤 곡선의 전반적인 방향을 직관적으로 알려줌으로써 추세의 패턴을 알 수 있게 도와줍니다.
☞ Add Cusum Column과 Add Cumsum Column의 기능은 다릅니다. - Cusum의 계산은 다음과 같습니다.
- “Cusum.tbl” 파일을 열고, Analyze >> Trend >> Add Cusum Column을 누른 후 다음과 같이 설정한다.
| index | Col1 | Cumsum_Col1 | 산식 |
|---|---|---|---|
| 0 | 5 | 0 | 5-5 = 0 |
| 1 | 3 | -2 | 0 + (3-5) = -2 |
| 2 | 4 | -1 | -2 + (4-3) = -1 |
| 3 | 8 | 3 | -1 + (8-4) = 3 |
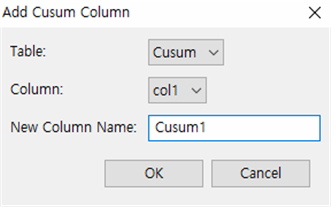
① Table : Cusum을 선택합니다.
② Column : col1을 선택합니다.
③ New Column Name : Cusum1이라고 입력합니다.
④ OK 버튼을 누릅니다.
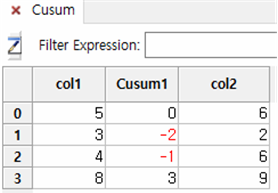
① Cusum1 칼럼에 Cusum값이 나타납니다.
By Regression Slope
- By Regression Slope는 회귀분석 결과 기울기를 보여주는 것이다. 회귀분석에 대한 자세한 설명은 통계 교과서를 참고하기 바랍니다.
- 『Trend.tbl 파일을 열고, Analyze >> Trend >> By Regression Slope을 누른 후 다음과 같 이 설정합니다.
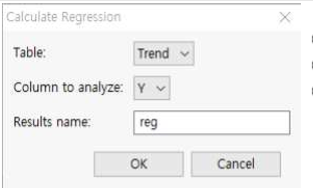
① Table : Trend를 선택합니다.
② Column to analyze: Y를 선택합니다.
③ Results Name : reg이라고 입력합니다.
④ OK 버튼을 누릅니다.
② Column to analyze: Y를 선택합니다.
③ Results Name : reg이라고 입력합니다.
④ OK 버튼을 누릅니다.

⑤ 기울기(Slope)는 약 0.806, 절편(Intercept)은 약 4.27, 상관계수(Correlation)는 약 0.0976, R2 값은 약 0.0095입니다.
By Average Slope
- By Average Slope는 평균 기울기를 구하는 것입니다. 예를 들어 다음과 같은 테이블이 있다고 가정하고, 이 경우 Average Slope 계산 결과는 3.75가 됩니다.
- Handshaking Slope : (2+3+4+6) / 4 = 3.75
- 『Handshake.tbl 파일을 열고, Analyze >> Trend >> By Average Slope을 누른 후 다음과 같이 설정합니다.
| index | Col_1 | 기울기 | 기울기 | 기울기 | |
|---|---|---|---|---|---|
| 0 | 1 | ||||
| 1 | 3 | 2 2(3-1)÷1(1-0) | |||
| 2 | 6 | 3 3(6-3)÷1(2-1) | |||
| 3 | 10 | 4 4(10-6)÷1(3-2) | |||
| 4 | 16 | 6 6(16-10)÷1(4-3) |
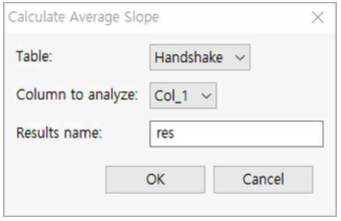
① Table : Handshake을 선택합니다.
② Column to analyze: Col_1를 선택합니다.
③ Results Name : res라고 입력합니다.
④ OK 버튼을 누릅니다.
② Column to analyze: Col_1를 선택합니다.
③ Results Name : res라고 입력합니다.
④ OK 버튼을 누릅니다.
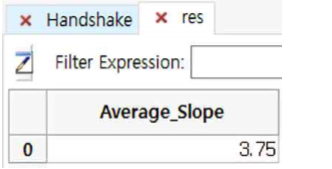
⑤ Average Slope가 3.75임을 알 수 있습니다.
By High_Low Slope
- By High_Low Slope는 minimum X, Y 와 maximum X, Y 간의 기울기를 구하는 것입니다.
- 『Trend.tbl 파일을 열고, Analyze >> Trend >> By High_Low Slope을 누른 후 다음과 같이 설정합니다.
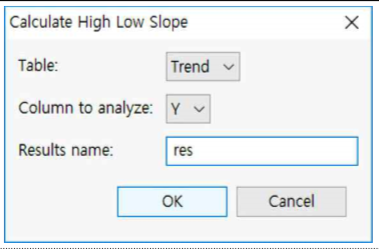
① Table : Trend를 선택합니다.
② Column to analyze: Y를 선택합니다.
③ Results Name : res라고 입력합니다.
④ OK 버튼을 누릅니다.
② Column to analyze: Y를 선택합니다.
③ Results Name : res라고 입력합니다.
④ OK 버튼을 누릅니다.
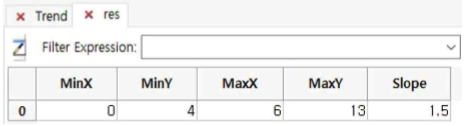
① High_Low Slope는 1.5임을 알 수 있습니다.
By Handshaking Slope
- By Handshaking Slope는 모든 점 사이의 기울기를 계산하는 것입니다. 예를 들어 다음과 같은 테이블이 있고, 이 경우 Handshaking Slope 계산 결과는 3.7083이 됩니다.
- Handshaking Slope : (2+2.5+3+3.75+3+3.5+4.333+4+5+6) / 10 = 3.7083
- 『handshake.tbl 파일을 열고, Analyze >> Trend >> By Handshaking Slope 메뉴를 누른 후 다음과 같이 설정합니다.
| index | Col_1 | 기울기 | 기울기 | 기울기 | |
|---|---|---|---|---|---|
| 0 | 1 | ||||
| 1 | 3 | 2 2(3-1)÷1(1-0) | |||
| 2 | 6 | 2.5 5(6-1)÷2(2-0) | 3 3(6-3)÷1(2-1) | ||
| 3 | 10 | 3 9(10-1)÷3(3-0) | 3.5 7(10-3)÷2(3-1) | 4 4(10-6)÷1(3-2) | |
| 4 | 16 | 3.75 15(16-1)÷4(4-0) | 4.333 13(16-3)÷3(4-1) | 5 10(16-6)÷2(4-2) | 6 6(16-10)÷1(4-3) |
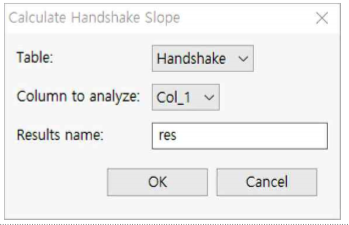
① Table : Handshake을 선택합니다.
② Column to analyze: Col_1를 선택합니다.
③ Results Name : res라고 입력합니다.
④ OK 버튼을 누릅니다.
② Column to analyze: Col_1를 선택합니다.
③ Results Name : res라고 입력합니다.
④ OK 버튼을 누릅니다.
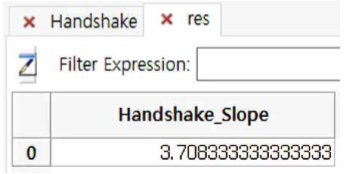
① Handshaking Slope는 3.7083임을 알 수 있습니다.
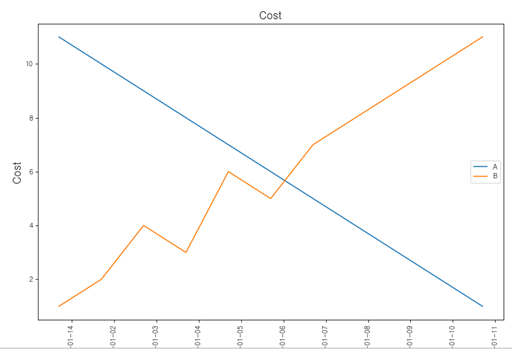
Chart 메뉴
- Chart메뉴는 테이블의 데이터를 참조하여 차트를 표시해주는 기능을 제공합니다.
- test1.tbl" 파일을 열고, Data >> Chart를 누른 후 다음과 같이 설정합니다.
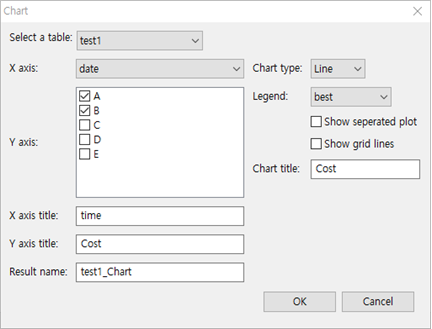
① Select a table : test1을 선택한다.
② X축은 date를 선택한다.
③ Y축은 원하는 칼럼을 체크한다. 여기서는 A와 B칼럼을 체크한다.
④ X축 타이틀을 정한다. 가능한 영어로 한다.
⑤ Y축 타이틀을 정한다. 가능한 영어로 한다.
⑥ Result name : test1_Chart로 한다.
⑦ Chart type : Line을 선택한다.
⑧ Legend : 여기서는 best를 선택한다.
Show separated plot을 체크하면 A칼럼과 B칼럼을 각자 차트에서 보여준다.
⑨ Chart title은 Cost라고 명명한다.
⑩ OK 버튼을 누른다.
② X축은 date를 선택한다.
③ Y축은 원하는 칼럼을 체크한다. 여기서는 A와 B칼럼을 체크한다.
④ X축 타이틀을 정한다. 가능한 영어로 한다.
⑤ Y축 타이틀을 정한다. 가능한 영어로 한다.
⑥ Result name : test1_Chart로 한다.
⑦ Chart type : Line을 선택한다.
⑧ Legend : 여기서는 best를 선택한다.
Show separated plot을 체크하면 A칼럼과 B칼럼을 각자 차트에서 보여준다.
⑨ Chart title은 Cost라고 명명한다.
⑩ OK 버튼을 누른다.
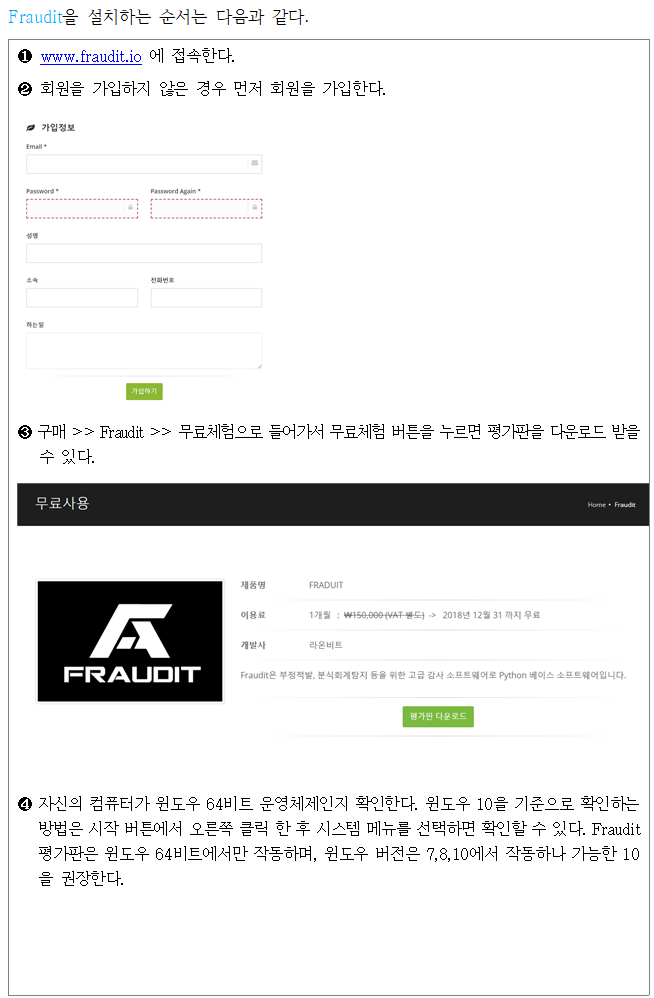
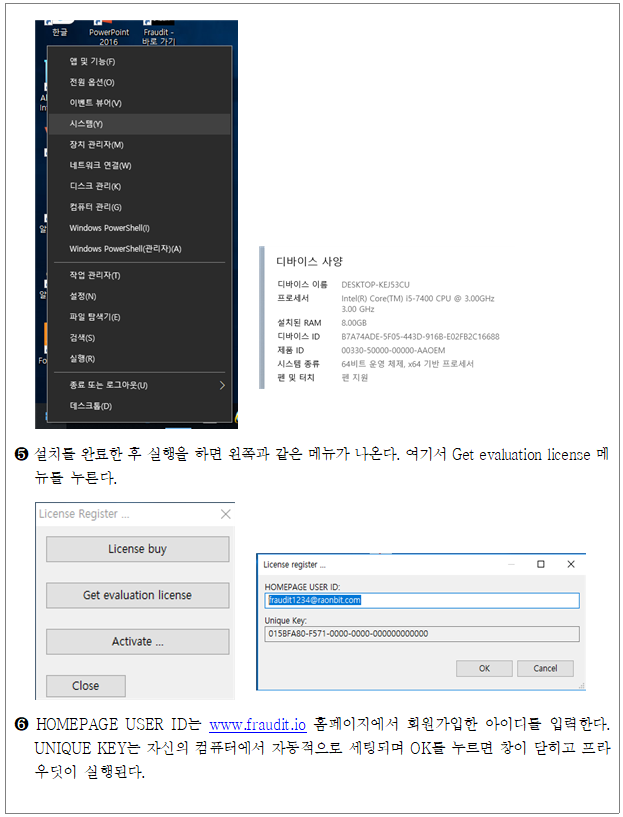
Fraudit의 설치
- Fraudit의 설치 안내 메뉴얼입니다.
Sampling 기법
1. 샘플링기초이론
- MUS(Monetary Unit Sampling)는 계정 잔액에 존재할 수 있는 왜곡된 금액을 평가하는데 사용되는 통계적 표본 추출 방법입니다. 화폐 단위 표본 추출 또는 확률-비례-크기 표본 추출이라고도 알려진 이 방법은 수년 간 사용되어 왔으며 감사인 사이에서 널리 받아 들여지고 있습니다.
- MUS는 다음과 같은 3가지 단계를 거칩니다.
① 적절한 샘플 규모를 결정하기
② 샘플을 선정하고 감사절차를 수행하기
③ 그 결과를 평가하고 모집단에 대한 결론에 도달하기 - MUS는 변수 샘플링에 사용되지만 실제로는 속성 샘플링 기법을 기반으로 합니다. 속성 샘플링 (attributes sampling)은 종종 통제 테스트에 사용되며 각 표본 항목을‘예외’또는‘예외가 아님’의 두 분류 중 하나에 분류할 수 있을 때 가장 적합한 기법입니다. 그러나, 금액적 잔액이 관심 대상이라면 이러한 ‘예외’의 정도가 다양하게 됩니다. 예를 들어 매출채권 $5,000의 잔액은 $50, $500 또는 심지어 $5,000까지 과대표시될 수 있기 때문입니다. 감사인은 분명히 더 큰 왜곡 표시에 더 관심이 있을 수 밖에 없습니다. 왜곡 표시의 정도나 비율을 화폐금액으로 환산하여 왜곡표시 정도를 조정하는 것을 아래에서 설명할 것입니다.
- MUS는 속성 샘플링을 기반으로 하기 때문에 통제 테스트를 위한 통계적 샘플 규모를 결정하는데 적용되는 절차와 동일한 절차에 따라 샘플 규모를 결정할 수 있습니다. 일반적인 방법은 AICPA에서 발간한 샘플 규모 표를 사용합니다.
- ‘모집단의 화폐금액’은 감사 대상이 되는 계정에 대하여 장부에 기록된 금액을 말합니다.
- ‘허용왜곡표시’는 개별적으로는 중요하지 않은 왜곡표시이지만 그 합계는 재무제표를 중요하게 왜곡시킬 수 있는 위험에 대처하고, 발견되지 않은 왜곡표시 가능액에 대한 여유를 제공하기 위하여 샘플을 설계할 때 결정하는 왜곡표시수준을 말합니다. ‘허용왜곡표시’는‘중요성’과 적은 금액이 될 것입니다(왜냐하면 허용왜곡표시는 개별적으로는 중요하지 않지만 합계는 왜곡 시킬 수 있는 최대 왜곡표시수준이며 중요성은 전체 재무제표 즉, 왜곡표시의 합계와 관련이 있기 때문입니다). ‘허용왜곡표시’와‘중요성’을 결정하는 것은 감사인의 유의적인 판단을 요구하므로 Fraudit이 그 자체를 결정해주는 것은 아닙니다.
- ‘샘플 규모 결정하는데 필요한 실제 입력 값은 허용 오차(tolerable rate of misstatement : TR)이며, 이는 [‘허용왜곡표시’ / 모집단 화폐금액]과 같습니다. 그러나 허용 오차는 대개 화폐로 표시되기 때문에 일반적으로 화폐로 TR을 입력할 수 있도록 설계하는 경향이 있습니다. TR과 샘플 규모 사이에는 역관계가 있습니다.
- Fraudit에서는 허용왜곡표시를 Tolerable Error라고 표현 합니다.
- ‘예상 오차율(Expected population exception rate)은 모집단에 존재할 것으로 예상되는 오차 율입니다. 예를 들어, 감사인이 예상 오차율을 2%로 하고, 기록된 모집단 금액이 $100,000이 라면 그 의미는 기록된 모집단 금액이 $2,000만큼 왜곡표시 되었을 것이라고 예상하는 것입니다. 예상오차를 직접 화폐단위로 입력가능하지만 결국 이는 백분율로 환산하는 것과 동일한 결과가 나옵니다. 예상 오차율은 샘플 규모와 직접 관련되며 허용 오차(TR)보다 상당히 작아야 합니다. 예상 오차율이 허용 오차(TR)에 접근하면 표본 크기가 엄청나게 커집니다. 예상 오차 율의 결정은 감사인의 판단에 따르는 것입니다. 이 결정을 하기 위해서, 감사인은 사전 감사결과, 최근 고객 인력의 변화 또는 왜곡표시 가능성을 보여줄 수 있는 기타 정보를 고려할 수 있다. 오차가 없을 것이라고 예상한다면 0을 사용할 수 있으나 오차의 margin을 허용하기 위해서 약간의 작은 예상 오차율을 사용하는 것이 바람직할 수 있습니다.
- Fraudit에서는 예상 오차율을 Expected Error라고 표현 합니다.
- ‘ ARIA는 모집단의 실제 왜곡표시가 허용왜곡표시를 초과함에도 불구하고 모집단이 중요하게 왜곡표시된 것이 아니라고 잘못 결론내리는 것을 기꺼이 받아들일 최대위험을 말합니다. ARIA 는 낮은 수준으로 설정해야 하지만, 정확한 값은 전반적인 허용 가능한 감사 위험, 통제 테스트 및 기타 입증감사(예:분석적 검토 절차)의 결과를 포함하여 여러 요인에 의해 영향을 받을 수 있습니다. ARIA를 결정하려면 감사인의 유의적인 판단을 요구하므로 Fraudit이 그 자체를 결정할 수 있게 하는 것은 아닙니다. ARIA와 샘플 규모 사이에는 반비례 관계가 있습니다.
- Fraudit에서는 ARIA를 Confidence Level이라고 표현 합니다.
- 샘플 규모가 원하는 것보다 큰 경우, 감사인은 아래의 옵션 중 하나 또는 그 이상의 조합을 사용하여 샘플 규모를 줄일 수 있습니다.
- tolerable misstatement를 증가시키기
- ARIA를 증가시키기
- 예상 오차율(Expected population exception rate)을 감소시키기
- 다른 계정에 할당된 허용왜곡표시를 줄일 수 있다고 가정할 때, 현실적으로 유일한 대안은 첫 번째인 허용왜곡표시를 증가시키는 방안입니다. 그러나 허용왜곡표시를 증가시키는 것도 다른 계정에 할당된 허용왜곡표시를 고려하여야 하므로 신중하게 결정하여야 합니니.
- ARIA는 신뢰수준을 의미하므로 이 단계에서 이를 변경하는 것은 설득력이 떨어지게 됩니다.
- 더욱이 예상 오차율은 모집단의 오차율에 대한 감사인의 최선의 추정치이며 이는 그 결과인 샘플 규모에 영향을 받아서는 안됩니다.
- 따라서 허용왜곡표시를 변경할 수 없다면, 감사인은 재무제표에 대한 의견을 뒷받침할 충분한 증거를 수집하기 위해 계산된 표본 크기로 감사 절차를 수행합니다.
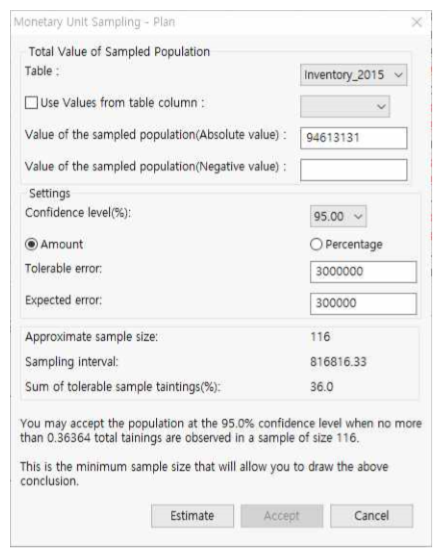
- 샘플 크기는 MUS sampling 테이블(예: AICPA audit guide sampling 테이블) 또는 Fraudit과 같은 소프트웨어를 사용하여 결정 할 수 있습니다. 앞서 설명한 개념에 따라 샘플 크기는 다음과 같이 산정합니다.
- 모집단 금액(Population dollar value : PV) → 94,613,131
- 허용왜곡표시(Tolerable misstatement : TM) → 3,000,000
- 예상 오차율(Expected population exception rate : EM) → 300,000
- Confidence Level → 75%
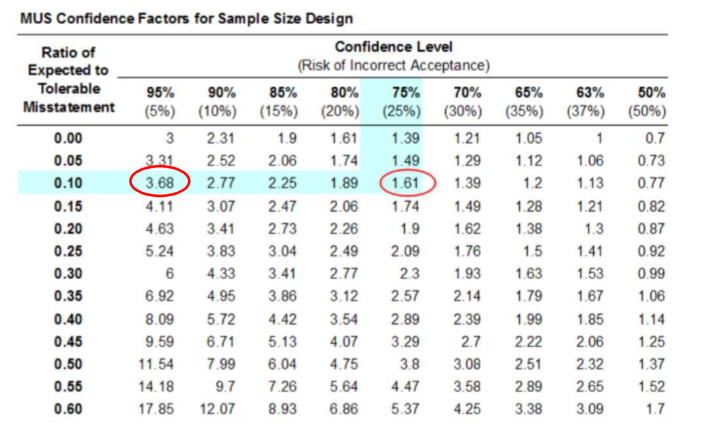
- MUS confidence factor를 다음과 같이 산정합니다.
- EM/TM = 0.10
- Confidence Level 75%
- MUS confidence factor = 1.61
- MUS 공식을 이용하여 샘플 크기 및 interval을 산정합니다.
- 샘플 크기 = MUS confidence factor × PV/TM
= 1.61 × (94,613,131/3,000,000)
= 50.78(round up) = 51 - Interval = 94,613,131 / 51 = 1,855,159
- 샘플링에 대한 분포를 어떤 것을 사용하느냐에 따라 Sampling Interval이 수작업과 약간 차이가 날 수 있습니다. Fraudit은 감마분포를 사용하므로 수작업 결과와 샘플링 interval이 약간 차이가 날 수 있습니다.
- MUS는 체계적인 샘플 선택이 종종 사용됩니다. 예를 들어, 누적금액이 아래와 같다고 가정하겠습니다.
- 수작업으로 구한 샘플 interval이 $815,630이라고 가정하겠습니다.
- 첫번째 interval은 1 $815,630사이의 1개의 무작위 번호(R)를 선택한다. 여기서는 10,000 을 선택합니다.
- 두번째 interval은 10,000 + I → 10,000 + 815,630 = 825,630이며, 세번째 interval은 10,000 + 2I → 10,000 + 815,630×2 = 1,641,260 입니다.
- 첫번째 샘플 선택 항목은 항목 2가 됩니다. 두번째 샘플 선택 항목은 항목 3이 됩니다. 세번째 샘플 선택 항목은 항목 4가 됩니다. 이러한 패턴이 총 116개가 될 때까지 계속되는 것입니다.
- 체계적인 샘플 선택을 사용할 때는 샘플 interval인 $815,630보다 큰 항목은 한 번 이상 선택 되며 샘플 interval보다 매우 큰 항목은 두 번 이상 선택될 수 있습니다. 따라서 선택된 항목 수는 계산된 샘플 Size보다 적을 수 있습니다. 여러 번 선택된 항목에 대해 예외가 기록된 경우에는 선택 한 경우마다 독립적인 관찰로 처리하므로 그 예외를 동일한 항목에 모두 적용합니다.
- 무작위 시작점을 다르게 선택한다면, 기본 파라미터(모집단 값 및 표본 크기)가 변경되지 않더라도 샘플이 변경될 수 있습니다. 이 결과를 사용하여 감사인은 위의 절차를 사용하여 실제 샘플 항목을 식별합니다.
- 마지막으로, 감사인은 각 샘플 항목에 적절한 감사 절차(예 :조회 확인)를 적용합니다. 발견된 예외에 대한 정보는 기록된 모집단 값에 대한 결론을 도출하는 데 사용됩니다.
- MUS는 속성 샘플링의 원칙에 근거하지만, 그 목표(모집단의 화폐적 왜곡표시 추정)는 전통적인 속성 샘플링의 목표와는 상당히 다릅니다. 특히, MUS는 다음 2가지 요소가 고려되어야 합니다.
- 모집단의 화폐적 왜곡표시 추정에 중요한 영향을 미치므로 예외의 유형(과대 평가 또는 과 소평가)이 고려되어야 합니다.
- 왜곡표시 추정시 예외의 정도를 측정하고 고려하여야 합니다. 예를 들어, 장부금액 $1,000이 실제 감사를 해보니까 $100이었다면 이는 $900(90%)만큼 과대 평가된 것인데 이는 실제 감사 결과 $990이고 $10(1%)만큼 과대 평가된 항목보다 가중치가 더 부여되어야 합니다
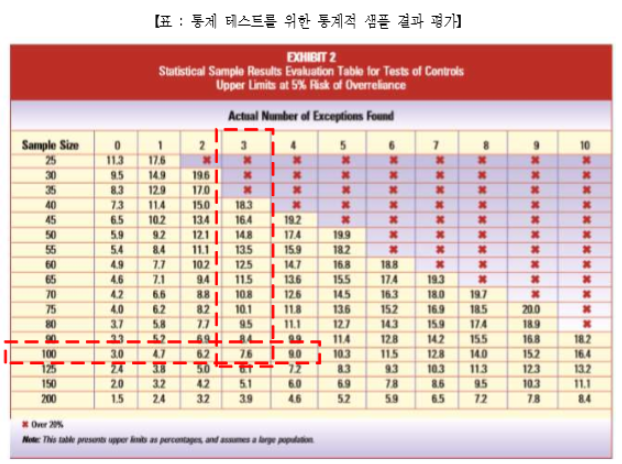
- MUS를 사용할 때 결과를 평가하는 방법에 대해서 설명하겠습니다. 감사인이 만약 100개 샘플에서 다음과 같은 4가지 예외를 탐지하였으며 각 항목은 한번만 선택되었다고 가정합니다.
- 상기 결과를 평가하기 위해서, 과대표시는 우선 과소표시와 분리되어야 합니다. 그러나 항목이 분리된 후에는 화폐적 왜곡표시를 추정하는데 사용되는 프로세스는 두가지 예외 유형에 동일하게 적용됩니다. 이 프로세스는 다음 표와 같이 통제 테스트 목적의 샘플 결과 평가표로부터 출발합니다.
- 즉, 표본 크기가 100이고 3번의 예외를 고려할 때, 다음 표는 통제 테스트 목적으로는 모집단의 실제 예외율이 7.6%를 초과할 확률이 5%라는 것을 나타냅니다. 이는 달리 표현하면 기록된 값이 $22,800*만큼 과대표시되었다고 볼 수 있습니다.
- 오차율(Expected population exception rate : EM) → 앞에서 300,000이라고 하였음
- Confidence Level → 앞에서 95%(ARIA 5%)라고 하였음
- 따라서, $30,000 × 7.6% = $22,800
- 통제 테스트 목적의 결과를 그대로 적용하는 것이 아니므로 MUS는 통제 테스트와 달리 감사인으로 하여금 7.6%의 총 상위 예외 한도를 몇 개의 레이어로 구분하도록 합니다.
- 첫번째 레이어는 예외가 발견되지 않았다면(0이었다면) 적용될 3.0%의 상위 한도입니다. 100 개의 샘플 크기에서 어떠한 예외도 발견되지 않았다 하더라도, 감사인은 모집단의 3% 이상이 예외라는 위험이 5%라고 결론내려야 합니다. 첫번째 레이어는 샘플 크기가 증가되면 될수 록 감소될 샘플 위험의 기본 허용치를 나타냅니다. 이러한 잠재적 왜곡에 관하여 알려진 것이 없기 때문에, 보수적인 접근법은 worst-case 시나리오(100% 왜곡)를 가정하는 것이며 이 레이어에 대해서는 $9,000($300,000×3%)의 추정되는 왜곡이 있을 것이라고 해석하는 것입니다.
- 두번째 레이어와 관련된 상위 한도는 1개 예외시의 값(4.7%)과 예외가 없는 경우의 값 (3.0%)의 차이인 1.7%입니다. 이러한 첫번째 예외가 발견되었기 때문에, 감사인은 이제 모집 단의 추가적인 1.7%가 예외를 포함하고 있다고 추정합니다. 추가적인 상위 한도는 유사하게 계산되며 점점 작게 됩니다.
- 각 레이어에 대한 화폐금액을 결정하기 위해서, 장부금액과 감사결과의 차이가 사용됩니다. 여기서 필요한 결정은 특정 레이어에 각 과대평가를 어떻게 할당하냐는 것입니다. MUS는 왜곡된 백분율에 근거하여 내림차순으로 예외에 대한 랭킹을 매기는 방식의 보수적인 접근방법을 취합니다. 왜냐하면, upper limit은 추가적인 레이어와 함께 점점 작아지므로, 내림차순으로 랭킹을 매김으로써 가장 차이가 큰 금액에 첫번째 레이어의 값이 적용되므로, 실제 예외에 대하여 가능한 가장 최대의 왜곡을 나타내기 때문입니다.
- 이제 Fraudit에서 샘플링 사례를 수행해보겠습니다. 먼저 예제파일인 『Sample.tbl』을 엽니다.
1.1. 샘플 규모를 결정하기
1.1.1. 화폐금액(Population dollar value)
1.1.2. 허용왜곡표시(tolerable misstatement)
1.1.3. 예상 오차율
1.1.4. Acceptable risk of incorrect acceptance (ARIA) : Confidence Level
1.1.5. 샘플규모가 원하는 것보다 큰 경우
1.2. 선정하고 감사절차를 수행하기
| 장부금액 | 누적금액 | Interval | |
|---|---|---|---|
| 1 | $5,000 | $5,000 | |
| 2 | $7,000 | $12,000 | 10,000 |
| 3 | $850,000 | $862,000 | 825,630 |
| 4 | $1,100,000 | $1,962,000 | 1,641,260 |
1.3. 결과 평가하기
| 장부금액 | 감사결과 금액 | 과대(과소)표시 금액 | |
|---|---|---|---|
| 1 | $1,650.00 | $572.55 | $1,077.45 |
| 2 | $1,200.00 | $900.00 | $300.00 |
| 3 | $975.00 | $159.90 | $815.10 |
| 4 | $700.00 | $770.00 | ($70.00) |

Sampling >> Monetary Unit-Plan >> Plan, Extract 메뉴를 선택합니다.
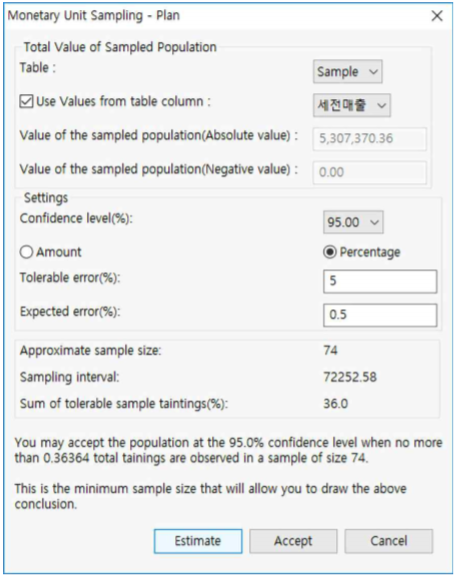
Table : Sample 선택
⒜ Use Values from table column 체크
⒝ 세전매출 칼럼 선택
⒞ Confidence level(%) : 95.00 선택
⒟ Percentage 라디오 버튼 선택
⒠ Tolerable error(%) : 5 입력
⒡ Expected error(%) : 0.5 입력
⒢ Estimate 버튼을 누른다.
☞ 박스 하단에 샘플 크기 선정에 대한 설명이 나옵니다.
⒣ Accept 버튼을 누르면 다음 화면으로 이동합니다.
⒜ Use Values from table column 체크
⒝ 세전매출 칼럼 선택
⒞ Confidence level(%) : 95.00 선택
⒟ Percentage 라디오 버튼 선택
⒠ Tolerable error(%) : 5 입력
⒡ Expected error(%) : 0.5 입력
⒢ Estimate 버튼을 누른다.
☞ 박스 하단에 샘플 크기 선정에 대한 설명이 나옵니다.
⒣ Accept 버튼을 누르면 다음 화면으로 이동합니다.
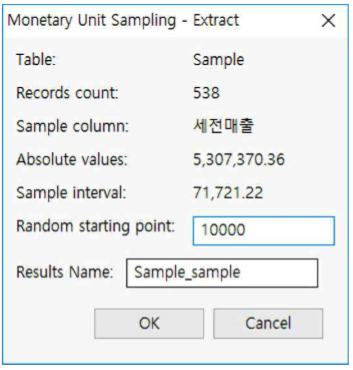
Random starting point : 10000 입력(이는 71721.22보다 작은 랜덤한 숫자를 넣으면 됩니다. 여기서는 10000을 입력한 것입니다)
Results Name : Sample_sample 입력
OK 버튼을 누릅니다.
Results Name : Sample_sample 입력
OK 버튼을 누릅니다.
세전매출_Audit 칼럼이 새로 생기고 샘플링 수는 74개인 것을 확인할 수 있습니다. 여기서 송장번호 A900059과 같이 금액이 interval을 크게 초과하는 경우에는 중복하여 샘플링 될 수 있으며 이는 각각 독립적인 경우라고 가정하면 됩니다.
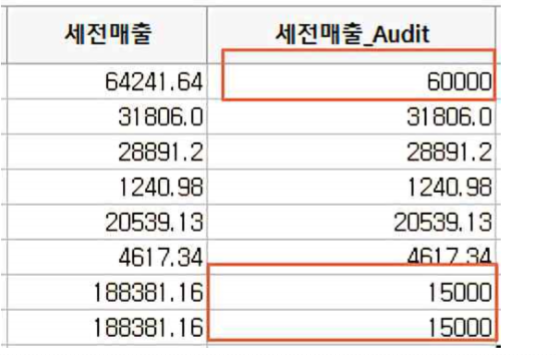
입증감사결과 64241.64의 장부금액은 실제 60000, 188381.16의 장부금액은 실제 15000이라고 할 경우
각각의 감사결과 금액을 수정해서 기입합니다. (188381.16은 각각 독립적인 경우라고 가정하므로 15000을 독립적으로 2번 기입합니다).

Sampling >> Monetary Unit-Plan >> Evaluation 메뉴를 선택합니다.
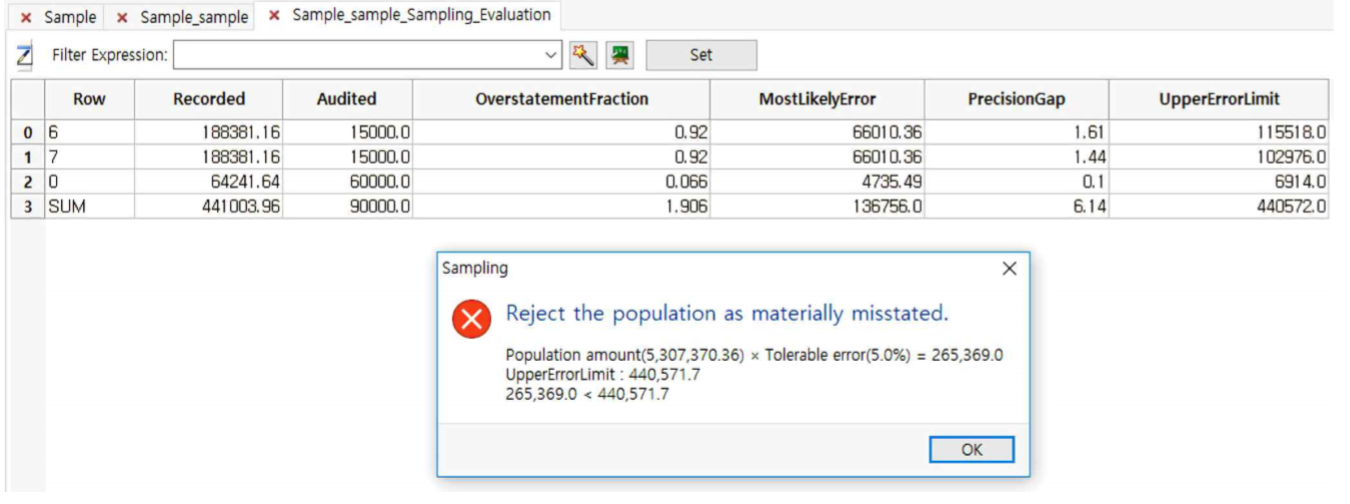 UpperErrorLimit의 합계인 440572.0이 모집단 5,307,370에 Tolerable Error인 5%를 곱한 금액인 265,369보다 크므로 모집단이 중요성 관점에서 왜곡표시되었다고 결론내릴수 있습니다. (즉, 모집단을 기각 한다는 의미입니다.)
UpperErrorLimit의 합계인 440572.0이 모집단 5,307,370에 Tolerable Error인 5%를 곱한 금액인 265,369보다 크므로 모집단이 중요성 관점에서 왜곡표시되었다고 결론내릴수 있습니다. (즉, 모집단을 기각 한다는 의미입니다.)
현금흐름표
- 현금흐름표 모듈의 경우 현재 더존 소프트웨어를 기준으로 다음과 같은 절차를 취하여야 합니다.
더존 소프트웨어로부터 분개장을 엑셀(또는 CSV)로 받습니다. 아래와 같이 더존 SMART A 프로그램 분개장 메뉴에서 오른쪽 클릭하여 데이터변환 메뉴를 선택한후 엑셀, CSV로 변환할 수 있습니다.
다운로드를 받은 엑셀은 기본적으로 암호가 설정되어 있으므로 이를 먼저 풀어서 저장을 하여야 합니다.
암호를 푼 엑셀 또는 CSV를 Fraudit에서 아래와 같이 불러와서 Fraudit 테이블로 전환합니다.
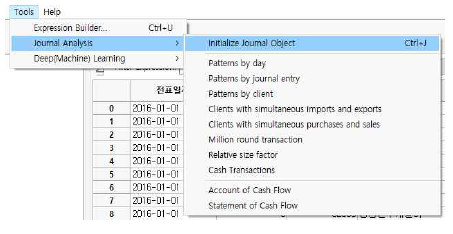
불러온 분개장 테이블에 대해서 다음의 메뉴를 적용합니다.
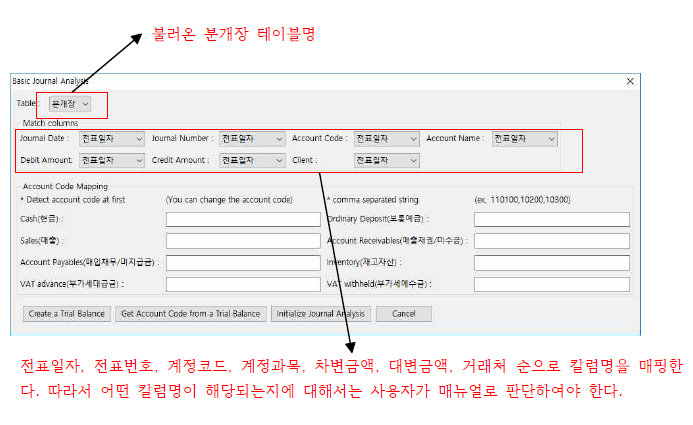
그림과 같이 매핑합니다.
분식회계
- 부도예측의 경우에는 재무정보 제공업체로부터 다운로드 받은 엑셀 자료를 토대로 만들었으므로 별도의 엑셀 템플렛을 만들기는 어렵습니다. 또한 입력하는 변수가 산식을 통하여 만들어야 하므로 이 부분은 아래와 같이 변수의 속성을 알려드릴 수 밖에 없다는 점 양해 말씀 드립니다.
- Beneish(1994)는 SEC로부터 지적받은 기업과 미디어에서 이익조작기업으로 확인된 기업에 대해 이익조작과 재무제표 변수간 관계를 검증한 결과 아래의 8가지 변수가 이익조작기업의 특성으로 나타난 것을 발견하였습니다.
부도예측 변수
| 변수 | 설명 |
|---|---|
| Attr5 | [(cash + short-term securities + receivables - short-term liabilities) / (operating expenses - depreciation)] * 365 |
| Attr9 | sales / total assets |
| Attr13 | (gross profit + depreciation) / sales |
| Attr15 | (total liabilities * 365) / (gross profit + depreciation) |
| Attr22 | profit on operating activities / total assets |
| Attr25 | (equity - share capital) / total assets |
| Attr27 | profit on operating activities / financial expenses |
| Attr31 | (gross profit + interest) / sales |
| Attr36 | total sales / total assets |
| Attr40 | (current assets - inventory - receivables) / short-term liabilities |
| Attr42 | profit on operating activities / sales |
| Attr48 | EBITDA (profit on operating activities - depreciation) / total assets |
| Attr52 | (short-term liabilities * 365) / cost of products sold) |
| Attr58 | total costs /total sales |
| Class | 0은 정상, 1은 부도(단, 이는 명목변수로 string 처리하여야 한다) |
분식회계 변수
| 변수 | 설명 |
|---|---|
| 채권회수기간지수 (DSRI) | 매출채권의 급격한 증가는 경쟁심화에 따른 신용매출 기준의 완화의 결과 일 수도 있고 가공매출을 통한 이익조작의 결과일수도 있다. 2개 년도에 걸쳐 매출채권과 매출액의 비율을 비교하는 이 지수의 급격한 증가는 매출액과 이익이 과대계상될 가능성과 정(+)의 관계가 있는 것으로 추정한다 |
| 매출총이익지수 (GMI) | 채권회수기간지수와는 달리 매출총이익지수는 전년도 매출총이익률을 당년도 매출총이익률로 나누어 계산한다. 따라서 이 지수가 1보다 크면 전기 대비 당기 수익성이 악화되었음을 의미한다. 영업악화가 예상되는 기업이 이익조작을 할 가능성이 더 높다면 이 지수와 이익조작확률사이에 정의 관계가 있을 것으로 추정한다 |
| 자산품질지수 (AQI) | 자산품질은 총자산 중 유형자산을 제외한 고정자산의 비율로서 측정한다. 이 지수는 미래효익의 불확실성이 상대적으로 높은, 달리 말해 실현가능성 위험 (realization risk) 이 높은 자산의 변화를 총체적으로 반영하고자 한다. 이 지수가 1보다 크다는 것은 기업이 보다 많은 지출을 자본화한데 기인할 수 있다. 따라서 이익조작확률과 이지수 간에 정의 관계가 있을 것으로 추정한다. |
| 매출성장성지수 (SGI) | 이 지수는 고성장 기업일수록 원활한 자본조달을 위해 이익목표치를 달성하기 위하여 회계분식을 할 가능성이 높다는 점에서 출발한다. 또한 고성장 시기에는 내부통제와 보고기능이 제조, 판매기능에 비해 상대적으로 덜 중시됨으로써 이익조작이 내부에서 견제되지 않을 가능성이 있다(Loebbeckeet al. 1989). 또한 고성장 기업의 성장률이 둔화되기 시작하면서 주가가 하락할 때 경영자가 성장세 둔화 우려를 불식시키기 위해 이익을 조작할 우려가 높다(Fridson 1993). 따라서 이 지수와 이익조작확률사이에 정의 관계가 있을 것으로 추정한다 |
| 감가상각지수 (DEPI) | 이 지수가 1보다 크면 자산 감가상각 속도가 완화되었음을 의미한다. 이는 예상 내용년수를 증가시키거나 보고이익을 증가시키는 회계처리방법을 채택했을 가능성이 높다고 해석할 수 있다. 따라서 이 지수와 이익조작확률 간에 정의 관계가 존재할 것으로 추정한다. |
| 판매관리비지수 (SGAI) | 대부분의 관리비가 고정비인 점을 감안하면 매출액 대비 판매관리비의 급격한 증가는 비경상적 판매노력의 투입이나 원가통제능력의 상실과 같은 부정적 상황의 결과일 수 있다. 따라서 이 지수와 이익조작확률 사이에 정의 관계를 발견할 것으로 추정한다. |
| 레버리지지수 (LVGI) | 부채계약의 위반을 피하기 위한 이익조작 유인을 반영하고자 총부채비율을 통해 레버리지의 변화를 측정한다. 이 지수와 이익조작확률 간에 정의 관계가 존재할 것으로 추정한다. |
| 총발생액비율 (TATA) | 총발생액은 순이익의 변화에서 영업활동현금흐름의 변화를 차감하여 계산하며 이를 총자산으로 나눈 총발생액비율을 통해 현금과 보고이익과의 괴리를 측정한다. 총발생액비율이 높을 수록 이익조작확률이 높을 것으로 기대한다. |